Snowplow Normalize dbt package



Normalize in this context means database normalization, as these models produce flatter data, not statistical normalization.
The package source code can be found in the snowplow/dbt-snowplow-normalize repo, and the docs for the macro design are here.
The package provides macros and a python script that is used to generate your normalized events, filtered events, and users table for use within downstream ETL tools. See the Model Design section for further details on these tables.
The package only includes the base incremental scratch model and does not have any derived models, instead it generates models in your project as if they were custom models you had built on top of the Snowplow incremental tables, using the _this_run table as the base for new events to process each run. See the configuration section for the variables that apply to the incremental model.
The incremental model is simplified compared to the standard unified model, this package does not use sessions to identify which historic events to reprocess and just uses the snowplow__session_timestamp (defaults to collector_tstamp) and package variables to identify which events to (re)process.
Model Design
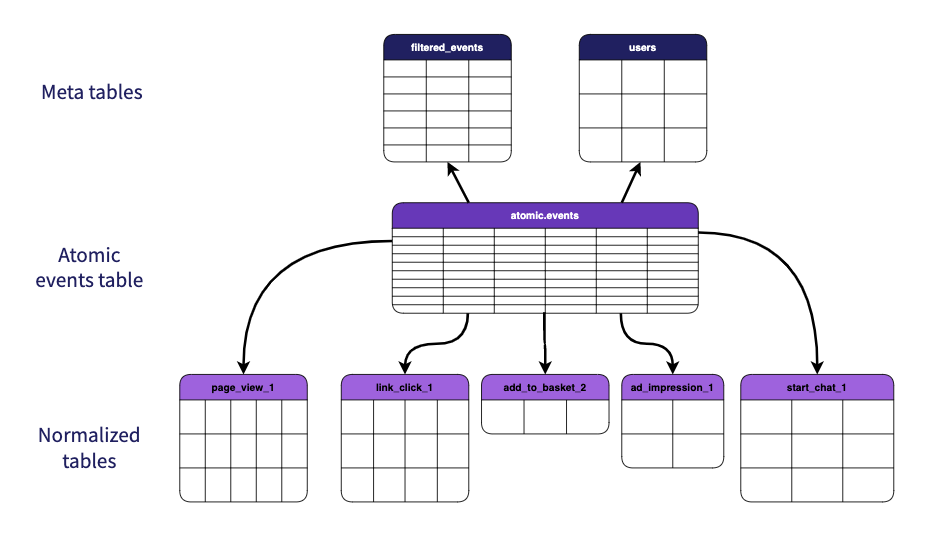
The package outputs models for 3 types of models: normalized events, a filtered events model, and a users model (different to the users table generated by the web or mobile packages).
Normalized Event Models
For each event_names listed, a model is generated for records with matching event type(s) and with the specified columns from the atomic.events table, including flattened (1 level) versions of your self-describing event or context columns. The table names are versioned based on the same versioning that is used to handle schema evolution with your data warehouse tables (see Updating Your Models section for potential issues with evolving schemas). In the case of multiple event types for a table you will need to provide the name and version of the table yourself. These can be combined into other models you create, or be used directly in downstream tools. The model file itself consists of lists of variables and a macro call.
For example, if you have 3 event_names listed as ['page_view'], ['page_ping'], and ['link_click', 'deep_link_click'] then 3 models will be generated, each containing only those respective events from the atomic events table.
Filtered Events Model
A single model is built that provides event_id, snowplow__partition_tstamp (defaults to collector_tstamp), and the name of the Normalized Event Model that the event was processed into, it does not include records for events that were not of an event type in your configuration. The model file itself is a series of UNION statements.
Users Model
The users model provides a more traditional view of a Users table than that presented in the other Snowplow dbt packages. This model has one row per non-null user_id (or other identifier column you specify), and takes the latest (based on collector_tstamp) values from the specified contexts to ensure you always have the latest version of the information that you choose to collect about your users. This is designed to be immediately usable in downstream tools. The model file itself consists of lists of variables and a macro call.
Package Overview
This package consists of two macros, a python script, and some example configuration files to help you get started, as well as the incremental models to build these normalized tables from:
-
normalize_events(macro): This macro does the heavy lifting of the package, taking a series of inputs to generate the SQL required to normalize theatomic.eventstable and flatten any self-describing event or context columns. While you can use this macro manually it is recommended to create the models that use it by using the script provided. -
users_table(macro): This macro takes a series of inputs to generate the SQL that will produce your users table, using the user identifier column you define, and any custom contexts from your events table. The identifier will be always be renamed touser_idin the output. -
snowplow_normalize_model_gen.py(script): This script uses an input configuration to generate the models based on a provided configuration file. See the operation section for more information.ymlsnowplow_normalize_model_gen.py helpusage: snowplow_normalize_model_gen.py [-h] [--version] [-v] [--dryRun] [--configHelp] [--cleanUp] configProduce dbt model files for normalizing your Snowplow events table into 1 table per event type.positional arguments:config relative path to your configuration fileoptional arguments:-h, --help show this help message and exit--version show program's version number and exit-v, --verbose verbose flag for the running of the tool--dryRun flag for a dry run (does not write/delete any files)--configHelp prints information relating to the structure of the config file--cleanUp delete any models not present in your config and exit (no models will be generated) -
example_normalize_config.json: This file is an example of an input to the python script, showing all options and valid values. For additional information about the file structure runpython dbt_packages/snowplow_normalize/utils/snowplow_normalize_model_gen.py --configHelpin your project root. -
example_resolver_config.json: This file is an example Iglu Resolver configuration. It supports custom iglu servers with API keys, but does not currently support accessing embedded registries. For more information please see the Resolver docs. -
models/base/: Models relating to the incremental nature of the package, processing only new events (and those covered by the lookback window).
Operation
If you are using dbt Cloud then you will need to run the model-generating script locally, as there is no way to do this in cloud, and then copy your models up to your Cloud environment. You'll still need to add the package to your packages.yml file in your project.
You will need to have python installed, and basic experience using the terminal and a text editor, but there is no need to install dbt. If you clone or download the package repo you can follow the instruction below, but remove the dbt_packages/snowplow_normalize from the front of paths when you see it.
In general, it should only be required to run the script in this package once to begin with, then only as/when you need to add new models based on new events or alter the contexts attached to existing ones. While it is possible to manually set the values and use the macros, it is not recommended due to the time it would take and the likelihood of making mistakes.
The script should always be run from the root of your dbt project (the same level your dbt_project.yml file is at).
Install python packages
Python versions between 3.7 and 3.10 (inclusive) are currently supported
The script only requires 2 additional packages (jsonschema and requests) that are not built into python by default, you can install these by running the below command, or by installing them by your preferred method.
pip install -r dbt_packages/snowplow_normalize/utils/requirements.txt
Configuration File
There may be changes to the config file between versions, this page will always contain the latest information but if you are using an older version you should call the python script with the --configHelp flag.
The configuration file is used to provide the information needed to generate the SQL models listed above. We use the schemas that are defined in your event tracking to ensure full alignment with the data and reduce the amount of information you need to provide.
The config file is a JSON file which can be viewed by running the python script with the --configHelp flag. The config file can be located anywhere in your project, but it must have the following structure. Note that you must provide at least one of event_columns, self_describing_event_schemas or context_schemas for each event listed.
- Field Description
- JSON Schema
- Example Config File
config(required - object):resolver_file_path(required - string): Relative path to your resolver config json, or"default"to use iglucentral onlyfiltered_events_table_name(optional - string): Name of filtered events table, if not provided it will not be generatedusers_table_name(optional - string): Name of users table, defaultevents_usersif user schema(s) providedvalidate_schemas(optional - boolean): If you want to validate schemas loaded from each iglu registry or not, defaulttrueoverwrite(optional - boolean): Overwrite existing model files or not, defaulttruemodels_folder(optional - string): Folder undermodels/to place the models, defaultsnowplow_normalized_eventsmodels_prefix(optional - string): The prefix to apply (with_) to all normalize model table names, if atable_nameisn't provided, defaultsnowplow
events(required - array):event_1(required - object):event_names(required - array): Name(s) of the event type(s), value of theevent_namecolumn in your warehouseevent_columns(optional (>=1 of) - array): Array of strings of flat column names from the events table to include to include in the modelself_describing_event_schemas(optional (>=1 of) - array):iglu:com.type url(s) for the self-describing event(s) to include in the modelself_describing_event_aliases(optional - array): array of strings of prefixes to the column alias for self describing eventscontext_schemas(optional (>=1 of) - array): Array of strings ofiglu:com.type url(s) for the context/entities to include in the modelcontext_aliases(optional - array): Array of strings of prefixes to the column alias for context/entitiestable_name(optional if only 1 event name, otherwise required- string): Name of the model, default is theevent_nameversion(optional if only 1 event name, otherwise required - string - length 1): Version number to append to table name. If (only one)self_describing_event_schemais provided the major version number from that is used, default1
event_2(optional - object)- ...
event_n(optional - object)
users(optional - if not provided will not generate users model - object)user_id(optional - if not provided will use defaultuser_idfield - object)id_column(required - string): Name of column or attribute in the schema that defines your user_id, will be converted to a string in Snowflakeid_self_describing_event_schema(optional - string):iglu:com.type url for the self-describing event schema that your user_id column is in, used overid_context_schemaif both providedid_context_schema(optional - string):iglu:com.type url for the context schema that your user_id column is inalias: (optional - string): Alias to apply to the id column
user_contexts(optional (>=1 of) - array): Array of strings ofiglu:com.type url(s) for the context/entities to add to your users table as columns, if not provided will not generate users modeluser_columns(optional (>=1 of) - array): Array of strings of flat column names from the events table to include in the model
{
"description": "Schema for the Snowplow dbt normalize python script configuration",
"self": {
"name": "normalize-config",
"format": "jsonschema",
"version": "2-1-0"
},
"properties": {
"config": {
"type": "object",
"properties": {
"resolver_file_path": {
"type": "string",
"description": "relative path to your resolver config json, or 'default' to use iglucentral only"
},
"filtered_events_table_name": {
"type": "string",
"description": "name of filtered events table, if not provided it will not be generated"
},
"users_table_name": {
"type": "string",
"description": "name of users table, default events_users if user schema(s) provided"
},
"validate_schemas": {
"type": "boolean",
"description": "if you want to validate schemas loaded from each iglu registry or not, default true"
},
"overwrite": {
"type": "boolean",
"description": "overwrite existing model files or not, default true"
},
"models_folder": {
"type": "string",
"description": "folder under models/ to place the models, default snowplow_normalized_events"
},
"models_prefix": {
"type": "string",
"description": "prefix used for models when table_name is not provided, use '' for no prefix, default snowplow"
}
},
"required": [
"resolver_file_path"
],
"additionalProperties": false
},
"events": {
"type": "array",
"items": {
"type": "object",
"properties": {
"event_names": {
"type": "array",
"items": {
"type": "string",
"minItems": 1
},
"description": "name(s) of the event type(s), value of the event_name column in your warehouse"
},
"event_columns": {
"type": "array",
"items": {
"type": "string"
},
"description": "array of strings of flat column names from the events table to include in the model"
},
"self_describing_event_schemas": {
"type": "array",
"items": {
"type": "string"
},
"description": "`iglu:com.` type url(s) for the self-describing event(s) to include in the model"
},
"self_describing_event_aliases": {
"type": "array",
"items": {
"type": "string"
},
"description": "array of strings of prefixes to the column alias for self describing events"
},
"context_schemas": {
"type": "array",
"items": {
"type": "string"
},
"description": "array of strings of `iglu:com.` type url(s) for the context/entities to include in the model"
},
"context_aliases": {
"type": "array",
"items": {
"type": "string"
},
"description": "array of strings of prefixes to the column alias for context/entities"
},
"table_name": {
"type": "string",
"description": "name of the model, default is the event_name"
},
"version": {
"type": "string",
"minLength": 1,
"maxLength": 1,
"description": "version number to append to table name, if (one) self_describing_event_schema is provided uses major version number from that, default 1"
}
},
"if": {
"properties": {
"event_names": {
"minItems": 2
}
}
},
"then": {
"anyOf": [
{
"required": [
"event_names",
"self_describing_event_schemas",
"version",
"table_name"
]
},
{
"required": [
"event_names",
"context_schemas",
"version",
"table_name"
]
},
{
"required": [
"event_names",
"event_columns",
"version",
"table_name"
]
}
]
},
"else": {
"anyOf": [
{
"required": [
"event_names",
"self_describing_event_schemas"
]
},
{
"required": [
"event_names",
"context_schemas"
]
},
{
"required": [
"event_names",
"event_columns"
]
}
]
},
"additionalProperties": false
},
"minItems": 1
},
"users": {
"type": "object",
"properties": {
"user_id": {
"type": "object",
"properties": {
"id_column": {
"type": "string",
"description": "name of column or attribute in the schema that defines your user_id, will be converted to a string in Snowflake"
},
"id_self_describing_event_schema": {
"type": "string",
"description": "`iglu:com.` type url for the self-describing event schema that your user_id column is in, used over id_context_schema if both provided"
},
"id_context_schema": {
"type": "string",
"description": "`iglu:com.` type url for the context schema that your user_id column is in"
},
"alias": {
"type": "string",
"description": "alias to apply to the id column"
}
},
"additionalProperties": false,
"required": [
"id_column"
]
},
"user_contexts": {
"type": "array",
"items": {
"type": "string",
"description": "array of strings of iglu:com. type url(s) for the context/entities to add to your users table as columns"
}
},
"user_columns": {
"type": "array",
"items": {
"type": "string",
"description": "array of strings of flat column names from the events table to include in the model"
}
}
},
"anyOf": [
{
"required": [
"user_contexts"
]
},
{
"required": [
"user_columns"
]
}
],
"additionalProperties": false
}
},
"additionalProperties": false,
"type": "object",
"required": [
"config",
"events"
]
}
{
"config":{
"resolver_file_path": "utils/example_resolver_config.json",
"filtered_events_table_name":"snowplow_events_normalized",
"users_table_name":"snowplow_context_users",
"validate_schemas": true,
"overwrite": true,
"models_folder": "snowplow_normalized_events",
"models_prefix": "snowplow"
},
"events":[
{
"event_names": ["page_view", "page_ping"],
"event_columns": [
"domain_userid",
"app_id",
"load_tstamp",
"page_url"
],
"context_schemas":[
"iglu:com.snowplowanalytics.snowplow/web_page/jsonschema/1-0-0",
"iglu:nl.basjes/yauaa_context/jsonschema/1-0-4"
],
"context_aliases": ["page", "yauaa"],
"table_name": "snowplow_page_events",
"version": "1"
},
{
"event_names": ["link_click"],
"event_columns": [
"domain_userid",
"app_id",
"refr_urlpath"
],
"self_describing_event_schemas": ["iglu:com.snowplowanalytics.snowplow/link_click/jsonschema/1-0-1"],
"self_describing_event_aliases": ["click"],
"context_schemas":[
"iglu:com.snowplowanalytics.snowplow/ua_parser_context/jsonschema/1-0-0"
]
}
],
"users":{
"user_id": {
"id_column": "userId",
"id_self_describing_event_schema": "iglu:com.google.analytics.measurement-protocol/user/jsonschema/1-0-0",
"id_context_schema": "iglu:com.zendesk.snowplow/user/jsonschema/1-0-0",
"alias": "true_user_id"
},
"user_contexts": ["iglu:com.snowplowanalytics.snowplow/ua_parser_context/jsonschema/1-0-0",
"iglu:com.iab.snowplow/spiders_and_robots/jsonschema/1-0-0"],
"user_columns": [
"domain_userid",
"network_userid",
"app_id"
]
}
}
An example configuration can be found in the utils/example_normalize_config.json file within the package.
You should keep your configuration file, and your resolver file if you have one, at your project level and not inside the the snowplow-normalize package to avoid them being overwritten/deleted when the package is updated.
Producing your models
To produce your models you need to run
python dbt_packages/snowplow_normalize/utils/snowplow_normalize_model_gen.py path/to/your/config.json
(or equivalent path in Windows) from the root of your dbt project. This will produce one .sql file for each of the event name specified in the events part of your configuration, one .sql file for the combined filtered events table if a name was provided, and one .sql file for your users table if schema(s) were provided. These files will be in your models folder in the sub-folder specified in your config.
Custom error messages have been added to the script to try and catch any issues and provide suggested resolutions to any issues such as invalid configurations or failing validation of schemas. If you persist in getting errors when validating schemas you believe you be correct, you can disable this validation by setting validate_schemas to false in your config.
Adding new models
To add new models for new types of events, simply add them to your config and run the model again. Note that overwrite must be set to true for your filtered events table model to include these new events, and that this will overwrite any manual changes you made to the other models generated by this script.
Updating your models
Adding or removing columns from your dbt model, either manually or by changes caused by a different schema version, without specifying the on_schema_change model configuration or directly altering the tables in your database, is very likely to result in unintended outcomes - either your new columns will not appear or dbt may return an error. Please see the dbt docs for what to do in this situation. If you need to backfill new columns regardless you can perform a rerun of the entire model following the instructions here (note using the --full-refresh flag will not work in this case due to the use of the Snowplow incremental logic).
If you wish to update your models, such as adding a new context, removing a column, or updating to a new schema version, you must update your config file and run the script again, ensuring the overwrite value is set to true. This will remove any custom changes you made to the model file itself and you will need to re-add these.
All events models will be updated including the filtered events table, it is not possible at this time to update just a subset of models.
As your schemas for custom contexts and unstructured events evolve, multiple versions of the same column may be created in your events table (depending on the type of data loader being used) e.g. custom_context_1_0_0, custom_context_1_0_1. When modeling Snowplow data it can be useful to combine or coalesce each nested field across all versions of the column for a continuous view over time.
The snowplow-normalize package handles this for you, all you have to do is make sure you add all the versions in the relevant config file parameter (self_describing_event_schemas / context_schemas):
"self_describing_event_schemas": ["iglu:com.snowplowanalytics.snowplow/geolocation_context/jsonschema/1-0-0", "iglu:com.snowplowanalytics.snowplow/geolocation_context/jsonschema/1-1-0"]
The columns will then appear as part of the derived model configuration and will then be coalesced when compiled.
{%- set sde_cols = ['UNSTRUCT_EVENT_COM_SNOWPLOWANALYTICS_SNOWPLOW_GEOLOCATION_CONTEXT_1_0_0', 'UNSTRUCT_EVENT_COM_SNOWPLOWANALYTICS_SNOWPLOW_GEOLOCATION_CONTEXT_1_1_0'] -%}
Removing specific columns
If you want to not select all columns from your self describing event or context then you can manually delete them from the lists in each model file, ensuring to delete the matching record in the *_types list as well. The same warning applies from Updating your models, and any overwriting run of the script will remove these changes.
Removing models
You can remove all models that don't exist in your config by running the script with the --cleanUp flag. This will scan the models_folder folder provided in your config and list all models in this folder that don't match those listed in your config file; you will then be asked to confirm deletion of these. If you may wish to re-enable these models at a later date you can disable them in your project instead.
If you have other models in the same sub-folder that were not generated via this package then this will attempt to delete those files.