Snowplow Attribution dbt package



You will need Unified version 0.4.0 to use Attribution version 0.2.0.
The package source code can be found in the snowplow/dbt-snowplow-attribution repo, and the docs for the macro design are here.
Although there is no direct dependency, by default the attribution package is dependent on the snowplow_unified_views as well as the snowplow_unified_conversions table created by the snowplow_unified dbt package. As long as the field names are matched you can use other source tables, too.
Overview
The Snowplow Attribution dbt package produces a set of incremental derived tables to provide a basis for in-depth Marketing Attribution Analysis on an ongoing basis. It allows you to attribute the value of a conversion to one or more channels and campaigns depending on the conversion pathway. As a result, it becomes possible to determine the revenue per pathway (channel or campaign), as well as ROAS (Return On Ad Spend - the amount of revenue that is earned for every dollar spent on advertising) once you have cost data for each marketing channel or campaign.
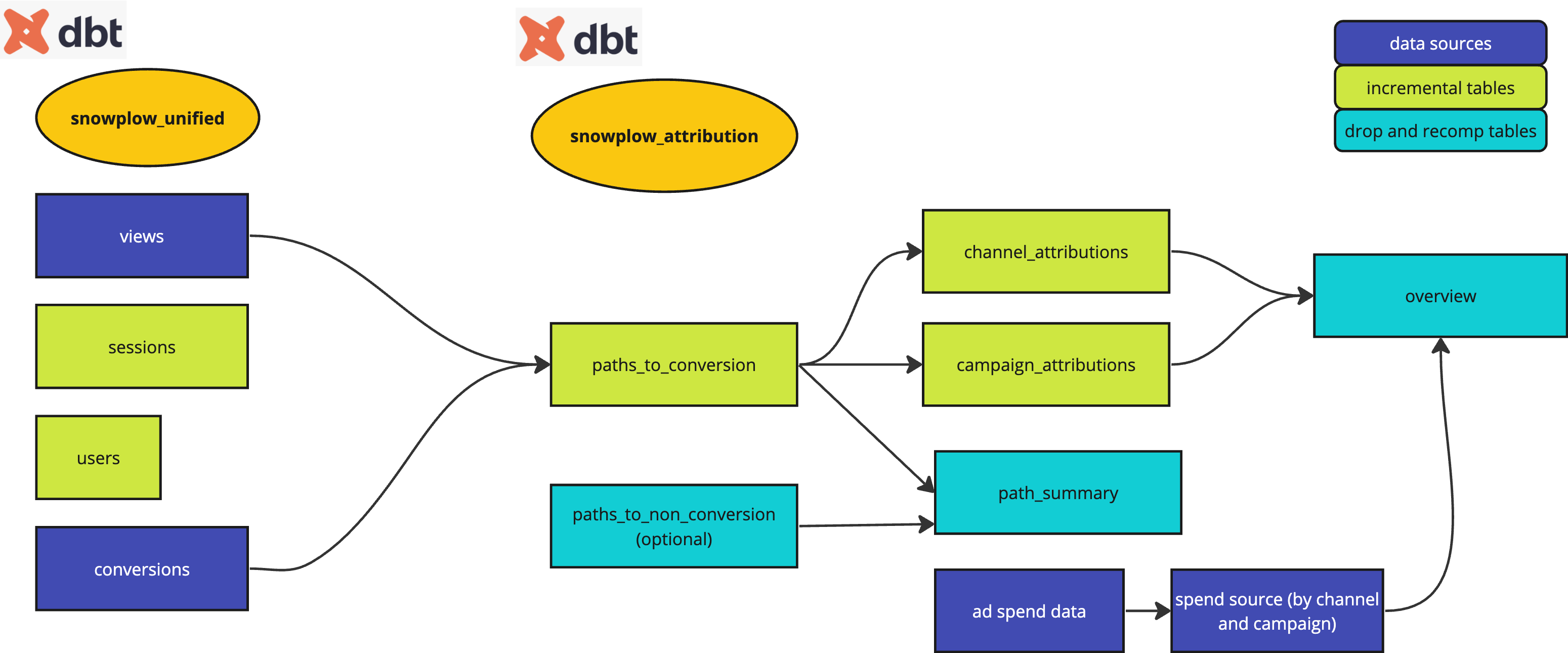
This package consists of a series of dbt models that produce the following tables:
snowplow_attribution_paths_to_conversion: Customer id and the paths the customer has followed that have lead to conversionsnowplow_attribution_campaign_attributions: By campaign path and conversion level incremental table that attributes the conversion value based on various algorithmssnowplow_attribution_channel_attributions: By channel path and conversion level incremental table that attributes the conversion value based on various algorithmssnowplow_attribution_overview: The user defined report view (potentially showing ROAS)snowplow_attribution_path_summary: For each unique path, a summary of associated conversions, optionally non-conversions and revenuesnowplow_attribution_paths_to_non_conversion: Customer id and the paths the customer has followed that have not lead to conversion. Optional drop and recompute table, disabled by default.
In the Quick Start section you will find a step-by-step guide on how to operate the package as a whole.
Attribution Models
The package currently offers 4 different attribution models all of which are calculated by default into both the incremental base tables and the report tables. If you would like to filter on them for reporting you can do so with var('snowplow__attribution_list'). Please note, however, that they will still be available for the incremental base tables.
first_touch: Assigns 100% attribution to the first channel in each path.last_touch: Assigns 100% attribution to the last channel in each path.position_based: The first and last channels get 40% of the credit each, with the remaining channels getting the leftover 20% distributed evenly.linear: Assigns attribution evenly between all channels on the path.


What is Marketing Attribution?
Marketing attribution determines which marketing tactics are contributing to sales or conversions by analysing the marketing touchpoints a consumer encounters on their journey to purchase. The aim is to determine which channels and marketing campaigns had the greatest impact on the decision to convert. There are many popular attribution models used by marketers which give insight into customers' behaviors, more specifically the pathways they took to purchase the product or service. This allows marketing teams to improve ROAS by changing marketing strategies and campaigns.
Benefits of using our package
The package was implemented with a glassbox philosophy in mind, making it very transparent for data consumers how the data is transformed. It is processed all in SQL inside your warehouse, there are no external dependencies e.g. extra Python packages or black-box ML algorithms.
It is also very flexible, there are no limitations on the touchpoints (it works on all channels or campaigns). You can use ad spend data from any 3rd party data sources. Although there are no direct dependencies on data sources either, it is recommended to be used together with the Unified Digital dbt package for a seamless setup without the need to overwrite default dbt macros.
It also does the heavy-lifting for you and provides you with incremental data models reducing unnecessary costs even if you would like to regularly analyze the data based on a shifting time window in your reports (e.g. last 30 days).
How to do Marketing Attribution with this package?
The purpose of this package is to allow an incremental, efficient way to do marketing attribution without having to read all your data every time.
In the below guide we will walk you through the data transformation process step-by-step in order for you to see how the source data changes downstream. This will give you and your team a transparent and easy-to-understand way to see how this package will lead you to valuable insights.
Sources you are going to need
1. Conversion source
You will also need a table where the conversion events are stored. If you use the snowplow_unified model and configure conversions to be modelled you will have this information in your derived.snowplow_unified_conversions table by default.
In case you store your conversion events elsewhere in the data warehouse (e.g. because those are transactional data that you decide you do not want to process through Snowplow), you can mutate that source table into the format of the conversions table (expand the Conversion formatting requirements section below for a list of all the conversion table columns) generated by the unified package, store it as a sql view, and refer to that in the variable snowplow__conversions_source (in the format of schema.view_name).
You could also union multiple sources (e.g. one transactional event data for automatic conversion events not dictated by user actions and then the rest, ending up in the unified_conversions table). Bear in mind though, that the incremental logic is dictated based on the last processed conversion in your conversion source, you need to make sure those tables are synced before the model is run.
Please bear in mind, if you would like to calculate the attribution for conversion events not processed by Snowplow, you would need to make sure these events contain a user_id type field which the package can rely on to find previous website visits for it to be able to attribute them to these conversions. Otherwise, your overall revenue will be more than the total attributed revenue.
Conversion formatting requirements
Fields to use (including the name) when creating the view:
cv_id: a unique identifier for each conversion, can be a dummy UUIDevent_id: a unique identifier for the conversion event, can be dummy UUIDsession_identifier(OPTIONAL): can be left out if it is the only source or NULL for unions with the unified.conversions tableuser_identifier: the user id field to be used for identifying pre conversion website visitsuser_id: the user id field to be used for identifying pre-conversion website visitsstitched_user_id: the user id field to be used for identifying pre conversion website visits (this will be used if conversion_stiching is enabled)cv_value: the conversion amountcv_tstamp: a timestamp field when the conversion took placedvce_created_tstamp(OPTIONAL): a timestamp field, can be left out if it is the only source or the same as the cv_tstamp for unions with the unified.conversions tablecv_type: you can name the types of conversions to differentiate them, if needed, it should not be left NULL/blankcv_tstamp_date: (DATABRICKS/SPARK ONLY): the date of thecv_tstampvalue
2. Path source
You will also need a source table to track your user journey / path with fields to be able to classify your marketing channels. The perfect table for this is your derived.snowplow_unified_views table (default):
Alternatively, you could use the derived.snowplow_unified_sessions table as well, but bear in mind that this will mean only the first channel/campaign will be counted within a session, and you will have to make sure the correct field reference is used in the snowplow_attribution_paths_to_conversion table by overwriting the paths_to_conversion() macro in your project (e.g first_page_urlhost instead of page_urlhost).
As for campaigns,
To fully finish the config you might need to overwrite the channel_classification() macro. In case your classification logic for attribution analysis needs to be the same as the one already configured in the snowplow_unified model you can simply leave the default macro which refers to that field. See the channel_group_query macro for more details.
3. Channel spend information (optional, but recommended)
You most likely have a warehouse with marketing (ad) spend information by channel and date, something like this:
To make it flexible to use what you already have, we suggest creating a view on top of the table you have, rename the fields that the model will use and add that view reference in var('snowplow__spend_source'). For more details on how to do this check out our Quick Start Guide.
4. User mapping source
In order to be able to attribute the value of a conversion to one or more channels and campaigns it is essential to have a shared user identifier field between the conversion events and the preceding website visits. If the Unified dbt package is used for the conversion and conversion path source, there are two out-of-the box stitching options to use:
-
By enabling BOTH the
snowplow__view_stitchingthesnowplow__conversion_stitchingin the unified package, both sources will get the lateststitched_user_idfield based on logged in user activity (see details here). By setting thesnowplow__conversion_stitchingvariable in the attribution package to true, the package will consider that field to take as a basis for both the conversion and the path source. Please note that this could potentially become a costly operation due to the volume of the snowplow_unified_views table, as after each run all the id fields will be updated by the latest mapping. -
Alternatively (default from v.0.3.0 onwards), the package will rely on the
snowplow__user_mapping_sourcedefaulted to thederived.snowplow_unified_user_mappingtable which will get used to take the latest logged in business user_id field per user_identifier, if available, otherwise it will keep the user_identifier value for both the conversions and conversion path source before the two are joined. -
When using custom sources or solutions, this logic could be overwritten in the dbt project using the
snowplow_attribution_paths_to_conversion()dispatch macro. In case the optionalsnowplow_attribution_paths_to_non_conversiontable is also in use, and it needs custom stitching logic, it is advised to disable it and create a custom model with the desired stitching logic.
Another option is if you alias your unique user id field as stitched_user_id in both your custom path and conversion source and set the snowplow__conversion_stitching variable to true, then the macro doesn't need to be altered but it will rely on these fields when linking conversions to paths.
One-off setup
Once you have the sources ready you need to adjust the package settings that fit your business logic. This has to be done once, otherwise your data might be misaligned due to the incremental logic or you would need to run a full-refresh:
Decide on your sessionization logic
By default, Snowplow only considers the first pageview of a session important from an attribution point of view and disregards campaign information from subsequent page_views. Google Analytics, on the other hand separates session as soon as campaign information is given. Set var('consider_intrasession_channels') variable to false in case you would like to follow Snowplow's logic, not GA's. If you opt for this calculation consider changing the var('snowplow__conversion_path_source') to {{ target.schema }}.derived.snowplow_unified_sessions for performance benefits.
Use the variable snowplow__conversion_hosts to restrict which hosts to take into account for conversions.
Filter unwanted / wanted channels & campaigns
You can specify a list of channels for the variable snowplow__channels_to_exclude to exclude them from analysis (if kept empty all channels are kept). For example, users may want to exclude the 'Direct' channel from the analysis.
You can also do the opposite, filter on certain channels to include in your analysis. You can do so by specifying them in the list captured within the variable snowplow__channels_to_include.
You can do either for campaigns, too, with the snowplow__channels_to_exclude and snowplow__channels_to_include variables.
Transform paths
In order to reduce unnecessarily long paths you can apply a number of path transformations that are created as part of user defined functions automatically in your warehouse by the package.
In order to apply these transformations, all you have to do is to define them in the snowplow__path_transforms variable as a dictionary. In case of remove_if_last_and_not_all and remove_if_not_all transformations, the transformation name is the key and a non-empty array is the value.
For other transformations (exposure_path, first_path, unique_path), no additional parameter is required, you can just use null as values. For more details on how to do this, check out the configuration page E.g.: {'exposure_path': null, 'remove_if_last_and_not_all': ['channel_to_remove_1', 'campaign_to_remove_1', 'campaign_to_remove_2']} Please note that the transformations are applied on both campaign and channel paths equally.
Path transform options
Paths to conversion are often similar, but not identical. As such, path transforms reduce unnecessary complexity in similar paths before running the attribution algorithm. The following transformations are available:
-
exposure_path (default): the same events in succession are reduced to one:A → A → BbecomesA → B, a compromise between first and unique -
unique_path: all events in a path are treated as unique (no reduction of complexity). Best for smaller datasets (small lookback window) without a lot of retargeting -
first_path: keep only the first occurrence of any event:A → B → AbecomesA → B, best for brand awareness marketing -
remove_if_last_and_not_all: requires a channel to be added as a parameter, which gets removed from the latest paths unless it removes the whole path as it is trying to reach a non-matching channel parameter: E.g target element:Apath:A → B → A → AbecomesA → B
A common requirement is to take the last non-direct clicks only into account during attribution analysis. If you use the remove_if_last_and_not_all path transform with direct as the parameter to remove it from the end of the path (unless they are all direct) the last-touch attribution results should show the outcome you need. You can also filter out the direct channels altogether with the snowplow__channels_to_exclude variable.
remove_if_not_all: requires a channel to be added as a parameter, which gets removed from the path altogether unless it would result in the whole path's removal: E.g target element:Apath:A → B → A → AbecomesB
Apart from this, you can also restrict how far in time (var('snowplow_path_lookback_days')) and steps (var('snowplow_path_lookback_steps')) you want to allow your path to go from the actual conversion event.
Redshift users starting from 0.6.0 are only allowed to have one path transformation
(e.g. either exposure_path or first_path). If using remove_if_last_and_not_all or
remove_if_not_all, only single-item arrays are allowed. In case of other supported targets there are no such limitations, multiple path transformations can be applied, if neeeded.
Other, macro based setup
To overwrite these macros correctly with those in your project, ensure you prefix the macro name by default__ in the definition e.g.
{% macro default__channel_classification() %}
case when (...)
{% endmacro %}
channel_classification macro
The
channel_classificationmacro is used to classify each marketing touchpoint from your path source deciding which marketing channel it was driven by. Be default it expects an already classified field calleddefault_channel_group. In case the Attribution package is used together with the Unified Digital package, it is advisable to classify your pageviews and sessions upstream using thechannel_group_guery()macro. For an in-depth guide on how to achive this check the channel group query macro documentation.
attribution_overview macro
Defines the sql for the view called attribution overview which provides the main report calculating the return on advertising spend (ROAS). In order to do that you would need a marketing spend table as an additional source which will contain the spend information by channel and or campaign with a timestamp to filter on the period. If you are happy with the logic of the macro, you can just define your spend table in the
snowplow__spend_sourcevariable and let it run.
paths_to_conversion macro
Macro to allow flexibility for users to modify the definition of the paths_to_conversion incremental table. By default the incremental table uses the
snowplow_unified_viewsandsnowplow_unified_conversionssource tables but this macro allows for flexibility around that. You can also restrict which conversion events to take
Adding tests (Optional)
Please note that the Unified data model allows nulls on user_identifier field, but the Attribution package does not, by default we filter out nulls within the paths_to_conversion macro when joining on the path_source and also on the conversion_source using the conversion_clause variable, which by default includes the null filter. We encourage users to add their own tests in the appropriate level (e.g. in the derived.snowplow_unified_views level) to make sure you don't accidentally exclude those events without user_identifier that are null (e.g. due to a tracking issue).
Output
Incremental data models to prepare for attribution analysis:
- The
derived.snowplow_attribution_paths_to_conversionmodel will aggregate the paths the customer has followed that have lead to conversion based on the path transformation and other limitations such as the path_lookback_step or path_lookback_days variable i.e. it combines the path and conversion source tables to produce an outcome. It looks like this:
| customer_id | cv_tstamp | revenue | channel_path | channel_transformed_path | campaign_path | campaign_transformed_path |
|---|---|---|---|---|---|---|
| user_id1 | 2022-06-11 15:33 | 20.42 | Direct | Direct | camp1 > camp2 | camp1 > camp2 |
| user_id2 | 2022-07-30 11:55 | 24 | Direct > Direct | Direct | camp1 | camp1 |
| user_id3 | 2022-06-08 20:18 | 50 | Direct > Direct | Direct | camp2 > camp1 | camp2 > camp1 |
| user_id1 | 2022-07-25 07:52 | 140 | Organic_Search > Direct > Organic_Search | Organic_Search > Direct > Organic_Search | Campaign 2 > Campaign 2 > Campaign 1 > Campaign 1 | Campaign 2 > Campaign 1 |
- The
derived.snowplow_attribution_channel_attributionsunnests the paths from paths_to_conversion into their separate rows and calculates the attribution amount for that specific path step for each of the sql based attribution models:
| composite_key | event_id | customer_id | cv_tstamp | cv_total_revenue | channel_transformed_path | channel | source_index | path_length | first_touch_attribution | last_touch_attribution | linear_attribution | position_based_attribution |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id1_Video0 | event_1 | user_id1 | 2023-07-07 13:05:55.000 | 200 | Video | Video | 0 | 1 | 200 | 200 | 200 | 200 |
| id2_Display_Other0 | event_2 | user_id2 | 2023-07-19 04:27:51.000 | 66.5 | Display_Other > Organic_Search | Display_Other | 0 | 2 | 66.5 | 0 | 33.25 | 33.25 |
| id3_Organic_Search1 | event_2 | user_id2 | 2023-07-19 04:27:51.000 | 66.5 | Display_Other > Organic_Search | Organic_Search | 1 | 2 | 0 | 66.5 | 33.25 | 33.25 |
- The
derived.snowplow_attribution_campaign_attributionsdoes the same, only for campaigns not channels.
Drop and recompute reporting tables/views:
- The
derived.snowplow_attribution_path_summaryshows the campaign/channel paths and the associated conversions (and optionally non-conversions, if thepath_to_non_conversionstable is enabled through its related variableenable_path_to_non_conversions)
| transformed_path | conversions | non_conversions | revenue |
|---|---|---|---|
| Direct | 3 | 25 | 94.42 |
| Organic_Search | 2 | 26 | 206.5 |
| Referral > Direct | 0 | 1 | 0 |
| Video | 1 | 2 | 200 |
| Organic_Search > Paid_Search_Other | 0 | 2 | 0 |
- The view called
derived.snowplow_attribution_overviewis tied to a dispatch macro of the same name which lets you overwrite it in your project, if needed. Given you specify yourvar('snowplow__spend_source')it will calculate the ROAS for you for each channel and campaign:
| path_type | attribution_type | touch_point | in_n_conversion_paths | attributed_conversions | min_cv_tstamp | max_cv_tstamp | spend | sum_cv_total_revenue | attributed_revenue | roas |
|---|---|---|---|---|---|---|---|---|---|---|
| campaign | first_touch | Campaign 2 | 2 | 1 | 2023-07-19 04:27:51.000 | 2023-07-25 07:52:34.000 | 100,000 | 206.5 | 206.5 | 0.002065 |
| campaign | last_touch | Campaign 1 | 3 | 1 | 2023-07-07 13:05:55.000 | 2023-07-30 11:55:24.000 | 100,000 | 364 | 364 | 0.00364 |
| channel | first_touch | Display_Other | 1 | 1 | 2023-07-19 04:27:51.000 | 2023-07-19 04:27:51.000 | 100,000 | 66.5 | 66.5 | 0.000665 |
| channel | first_touch | Organic_Search | 2 | 0 | 2023-07-19 04:27:51.000 | 2023-07-25 07:52:34.000 | 100,000 | 206.5 | 0 | 0 |
Manifest table
We have included a manifest table to log information about the setup variables each time the paths_to_conversion incremental table runs to help prevent and debug issues.