Introduction to Snowplow entities
When you track an action or behavior, the information about the objects, users, and context in which the action occurred is just as important as the action itself. In Snowplow tracking, we use entities to capture this contextual data. They're reusable building blocks that make your tracking easier to implement, and your data easier to analyze.
What we now call "entity" or "entities" was previously called "context". You'll still find context or contexts used in many of the existing APIs, database column names, and documentation, especially to refer to a set of multiple entities.
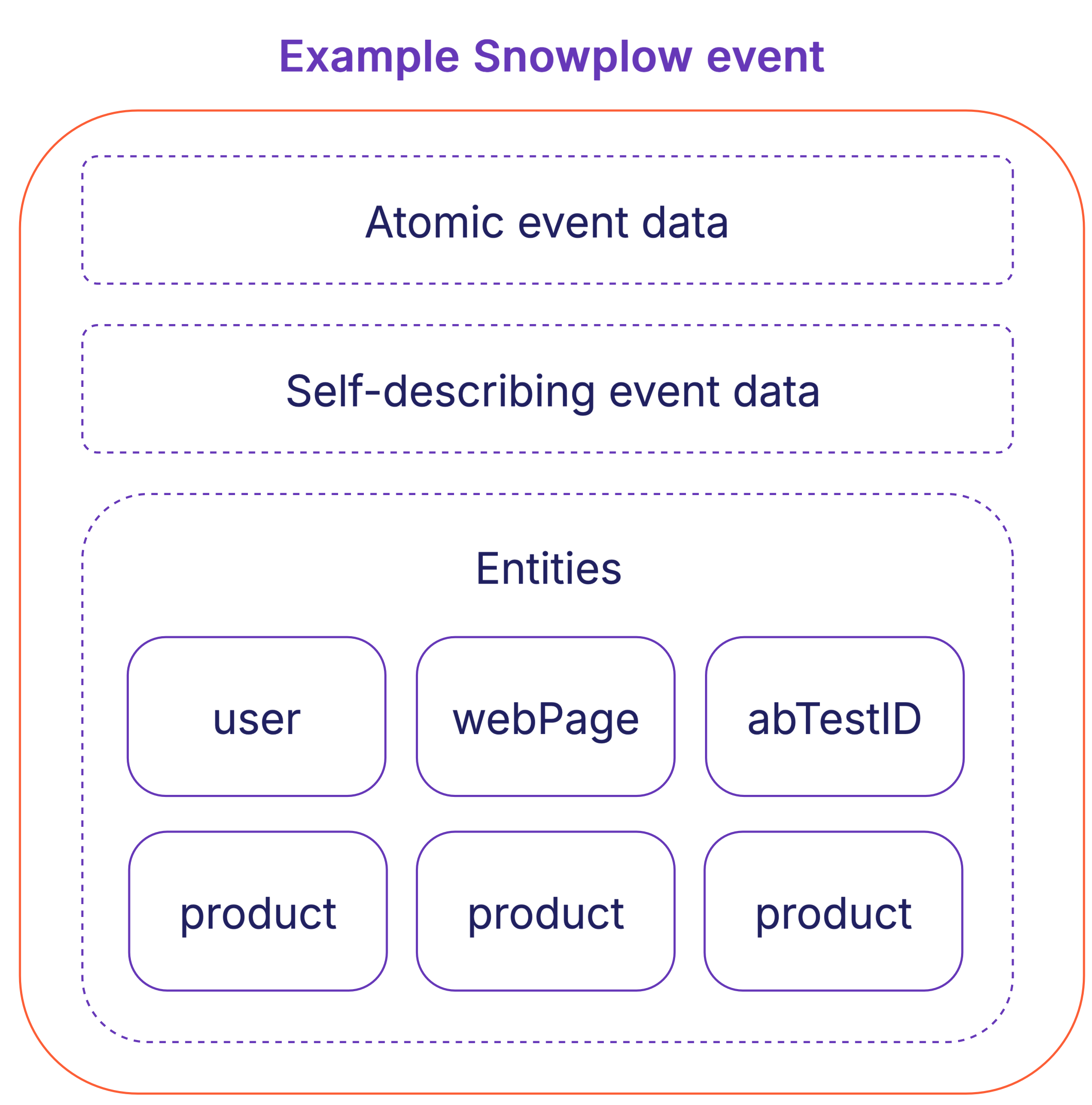
For example, when tracking a "search" event, you might want to capture information about:
- The user who performed the search
- The web page where the search was made
- The products that were returned in the search results
- Any A/B test variations that were active on the page
- And so on
The event data might include fields such as the search term, number of results, and time taken to perform the search. These fields are specific to the "search" event.
The user, webPage, A/B test variation, and products data isn't specific to that event, and can be defined and tracked as entities:
The user who triggered the search event might go on to generate a link_click event. You might want to capture data on:
- The user who clicked the link
- The web page where the link was clicked
The same user and webPage entities can be reused for this event.
Every Snowplow event can have entities attached to it. They can be of the same or different types.
How to track entities
Snowplow provides a number of entities out-of-the-box. You can configure your trackers to attach certain entities automatically to all events. For example, the web trackers add a webPage entity to all events by default.
Trackers add other out-of-the-box entities based on event type. For example, if you track a Snowplow media play event, the tracker will automatically add media_player and media session entities to it.
Check out the out-of-the-box data section to find out more about the entities that come with Snowplow trackers.
Some enrichments add entities to events in stream. For example, the cross-navigation enrichment adds a cross_navigation entity to events based on the cross-navigation querystring.
Custom entities
Check out our tracking plan guide for best practice on designing entities.
Snowplow provides tooling to help you define your own custom entities. Read more about tracking custom data here.
Entities are defined by schemas
Like most Snowplow events, entities are based on self-describing JSON schemas. As such, they can include arbitrarily complex data, and are versioned. You can evolve your entity definitions over time.
Each entity consists of two parts:
schema: a reference to a schema that describes the name, version and structure of the entitydata: the entity data as a set of key-value properties in JSON format
Find out in the warehouse tables fundamentals page about how entities are structured in the data warehouse.