Introduction to Data Products
Data products are Snowplow's solution to helping organizations more easily create and democratise behavioral data. By creating well-documented datasets, that are both human and machine readable, you can more easily collaborate around data & unlock self-service analytics at scale.
With data products, you can:
- Set clear ownership for the data being created
- Make tracking implementation easier
- Deliver better governance around your data
- More easily communicate what the data means and how to use it
- Collaborate more effectively with the various teams involved in delivering value from your data
- Drive a self-serve culture around data across your organization
What is a Data Product
A data product is a well documented dataset. By documenting what data you are collecting, where, the meaning of that data and how to use it, you can break down the barriers that exist today between the many teams involved in the data value chain (i.e. from those implementing the tracking to those analysing the data).
At its core, a data product has:
- An explicit owner; that is responsible for maintaining and updating the data over time
- Consumers; who use the data to deliver use cases and are impacted by upstream changes
Data products at Snowplow are underpinned by the concept of a data contract. They act as a formal agreement between the producers of data products and the consumers of data products, and support better collaboration around the data being created.
We have always believed in the value of data contracts at Snowplow; our tech is underpinned by event and entity schemas that describe upfront the structure of the data and ensure that the data conforms to that structure as it is processed by your pipeline. This schema technology forms the foundations of a data contract, but data products take this to the next level to bring enhanced quality, governance and discoverability to the data that you create.
Examples of data products:
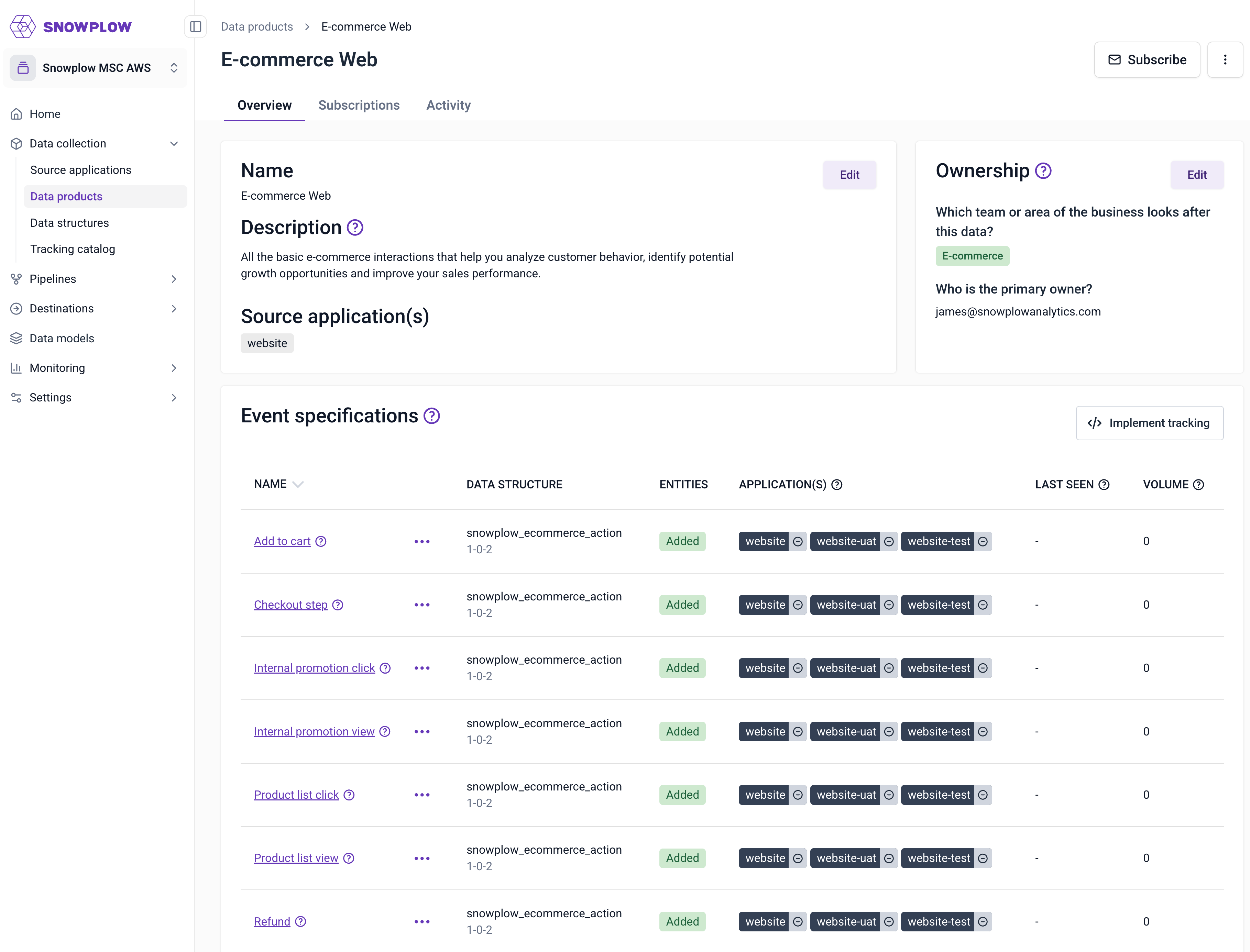
- E-commerce Web
- Media Web
Key elements of a Data Product
The Source Application/s it is part of; a data product is referencing the Source Application/s that is spanning across.
Benefits:
- Have a clear view in which application the data product is implemented in, which domains it spans and the related application context information it will have available by default in the dataset.
An owner; data products are typically split by domain with each data product having an explicit owner that is responsible for the maintenance and evolution of that data.
Benefits:
- Know who to go to when new data is required for a particular domain or when there is an issue with the data, breaking down the barriers between data producers and data consumers
Event specifications; these describe each event that is collected as part of the data product, on which applications they are triggered and where, the event data structure to validate against, and the entities to attach to each event (e.g. user, product etc).
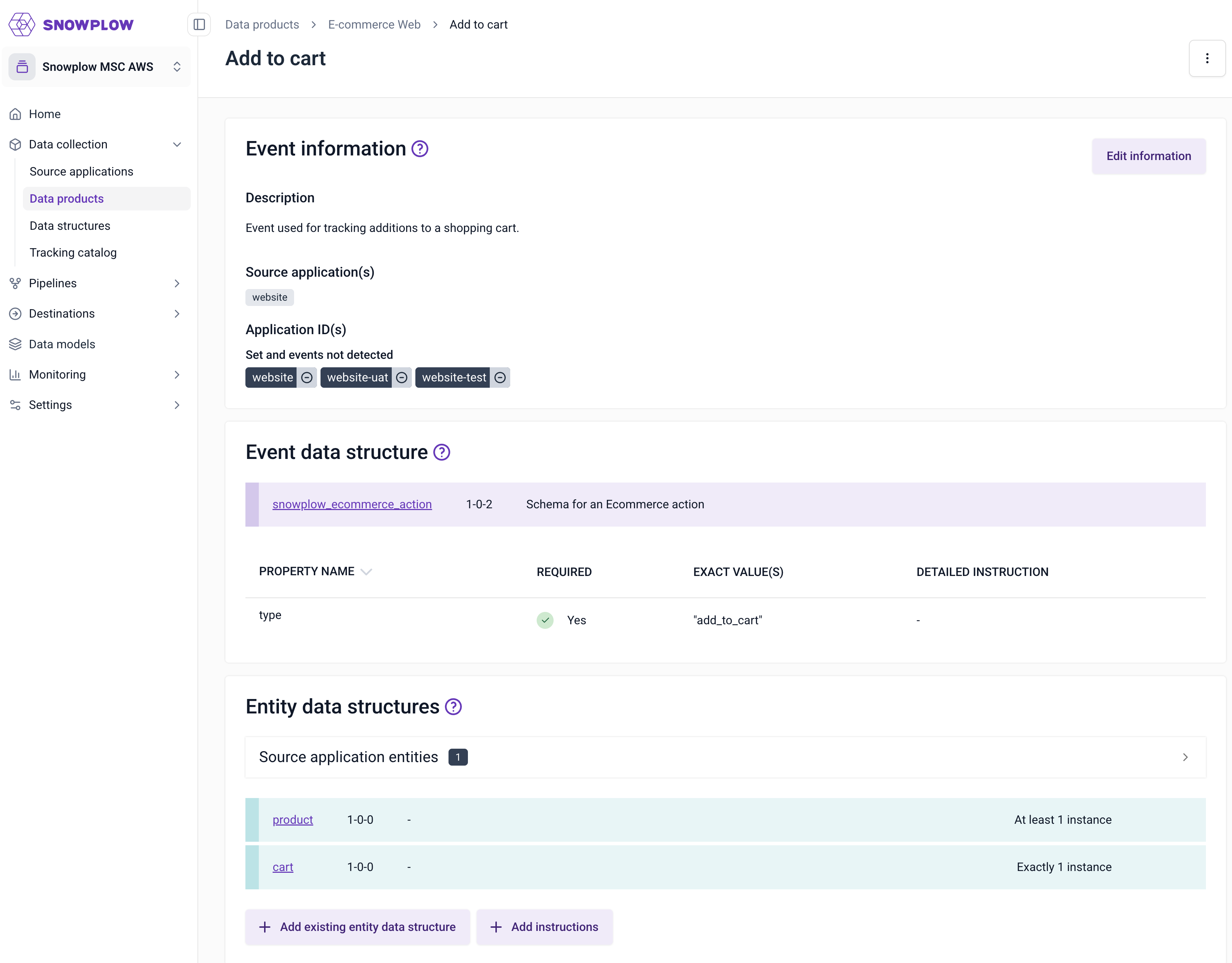
Benefits:
- Provide implementation details to developers implementing tracking (see section on Snowtype for further details)
- Provide documentation around the semantics of the data that you are creating, to enable analysts, data scientists, analytics engineers with data discoverability
Subscribers; allow colleagues to express an interest in understanding changes that are made to the data within a Data Product, usually because the data is being used in a downstream data model or Data Model Pack.
Benefits:
Break down the barriers that exist between data producers and data consumers, by providing:
- data producers, with visibility of how the data is being used downstream and the implications of any changes
- data consumers, with notifications when changes are made to a Data Product so that they can make any necessary changes to their models, reports etc.
Change history; a complete audit log of the changes that have been made to the data product, including changes to existing data and new data that has been added over time.
Benefits:
- Enhances accountability and transparency by providing a clear audit trail of all data modifications, fostering confidence in data integrity
Volume metrics; data products can detect events ingested in your pipeline that match the configured event specifications. This allows your team to monitor occurrence-related metrics for events being tracked with specific event specification IDs.
Benefits:
You will be able to view several items in the UI that help detect anomalies or potential misconfigurations in trackers that are either not sending the expected events or are using incorrect application IDs. This is particularly useful during the development phase when implementing tracking for a specific application using Snowtype. These elements include:
- A counter for each event specification, showing the total number of events detected from the tracked application IDs in the last 30 days.
- A 'last seen' field for each event specification, indicating when the last event matching the event specification ID was detected.
- A list of application IDs from which events are being tracked, displayed for each event specification. For each application ID, a status will be shown with different colors:
- Green: Event specifications are being tracked and identified with the specific application ID inherited from the configured source applications.
- Gray: No event specifications are being tracked for an application ID inherited from the configured source applications.
- Yellow: Event specifications are being tracked for an application ID that has not been configured or inherited from the source applications.
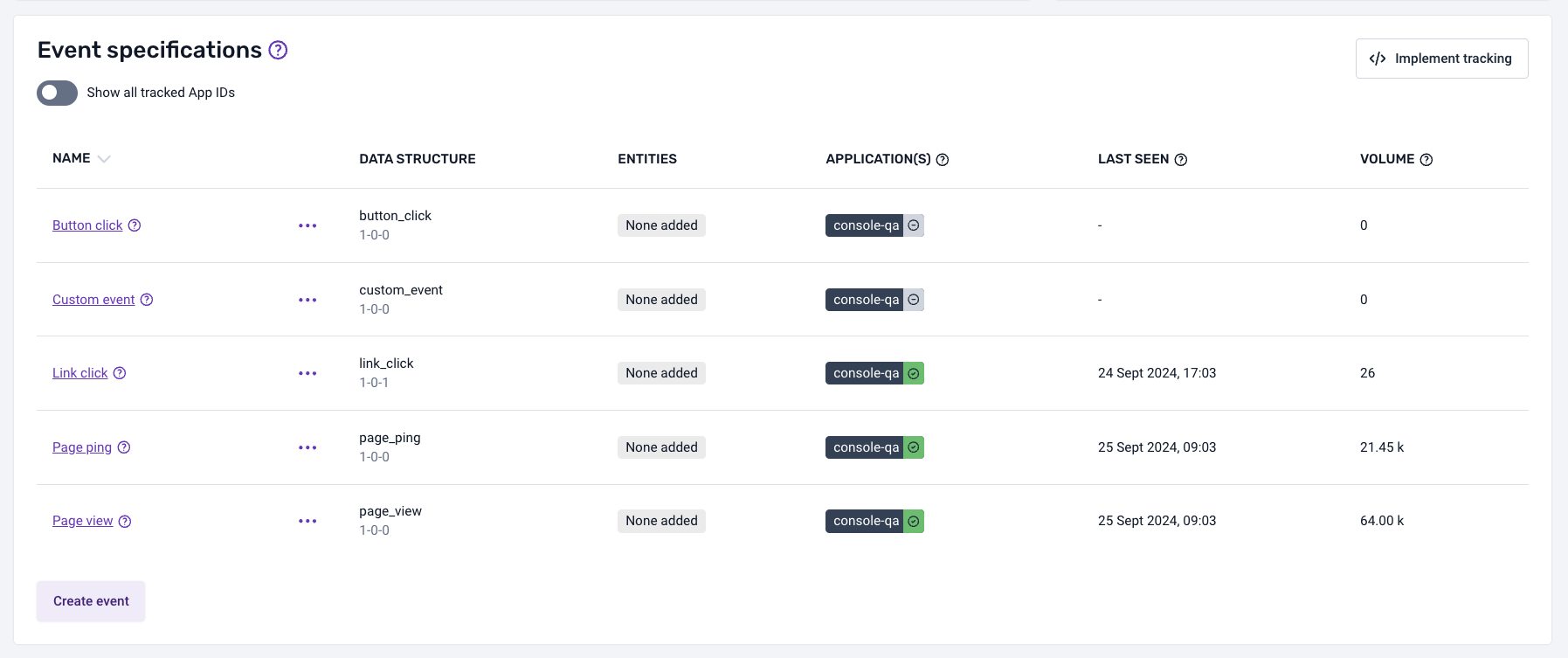
Some data products, such as Base Web and Base Mobile, contain standard events (e.g., page pings, link clicks, screen view, application install).
For these data products, the volume metrics will behave differently:
If no standard events are being tracked with an application ID different from those inherited from the source applications set up in the data product, the behavior will be the same as for a normal data product.
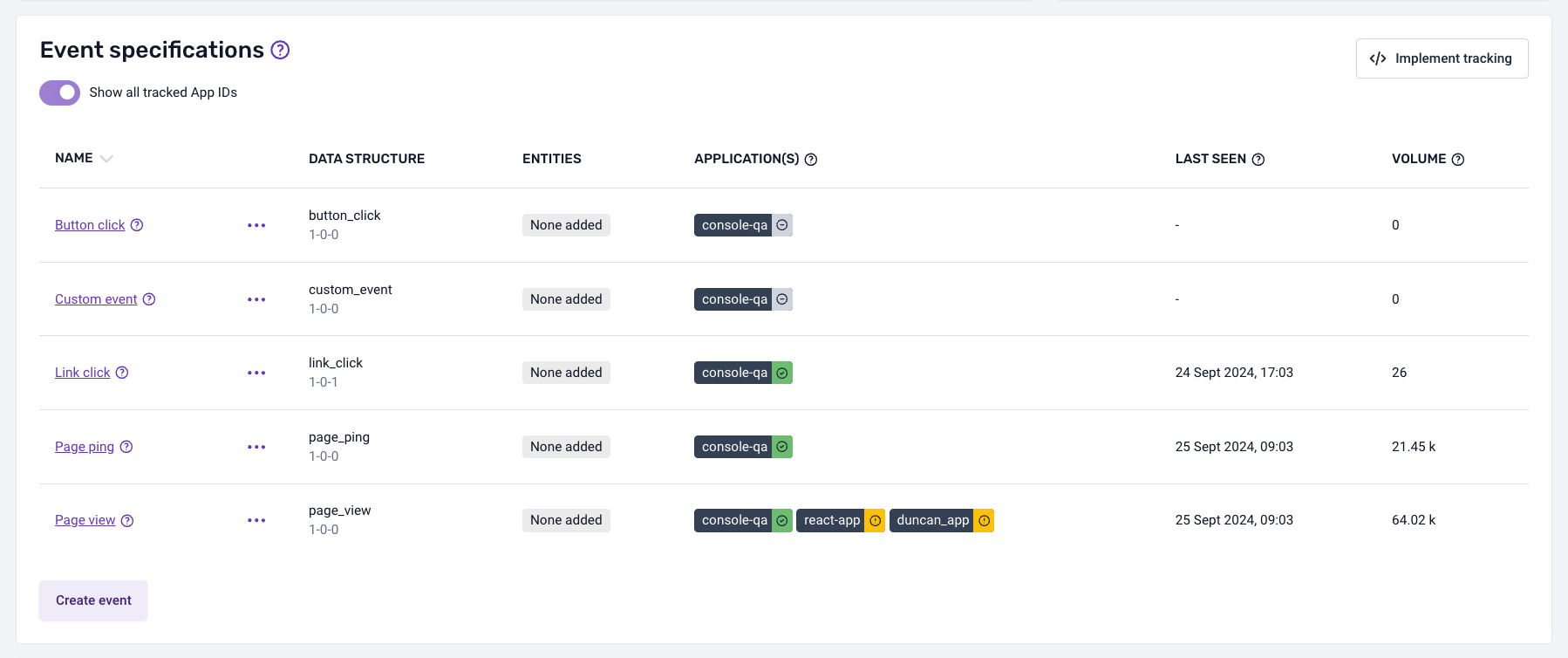
If standard events are being tracked with application IDs different from those inherited from the source applications set up in the data product, a toggle will appear above the event specification list.
This toggle will be disabled by default, so the metrics displayed will relate only to the application IDs inherited from the source applications set up in the data product.
If the toggle is enabled, it will show the metrics for all the application IDs found for the standard events (not just the ones inherited from the data product).
How data products help with governance, data quality and data discoverability
The data structures that you attach to your event specification describe the structure of the data. They validate that the values of the properties contained within your events and entities are valid as they pass through your pipeline.
The event specification describes a specific implementation of an event. It is a narrower definition of your event than a data structure - not only do they describe the structure of the data (by attaching the relevant data structure to validate against), they also allow you to define the right values for fields when the event gets triggered and the entities that need to be attached.
NB: the event specifications are not enforced by your pipeline (for example, we don’t yet validate that the correct entities are attached to an event).
By adding screenshots, and descriptions to the event specification, you are also able to communicate the semantics of the data to those that want to analyse it. In this way you can ensure that the data is represented accurately when being used to derive insights and make decisions by the many teams using the data downstream.
A data structure can be used across event specifications, and across data products. In doing so, you can ensure you consistently track business critical events and entities (for example, your "product" entity) across your organisation. Having the ability to use centralised event and entity schemas in this way, means that you are able to better govern the structure of the data across an organisation whilst also empowering teams to manage their own specific implementation of events via data products.
To understand how to get started with data products, see Defining the Data to collect with Data Products for further details.