Users and identity stitching
Identity stitching is the process of taking various user identifiers and combining them into a single user identifier, to better identify and track users throughout their journey on your site/app.
Stitching users together is not an easy task: depending on the typical user journey the complexity can range from having individually identified (logged in) users, thus not having to do any extra modeling to never identified users mainly using the same common public device (e.g. school or library) where it is technically impossible to do any user stitching. As stitching is a reiterative process as it constantly needs to be updated after each incremental run for a desirably large range of data, compute power and extra expenses as well as time constraints may limit and dictate the best course of action.
Session stitching
For the out-of-the-box user stitching we opt for the sweet spot method: applying a logic that the majority of our users will benefit from while not introducing compute-heavy calculations. We do this in our core dbt package, the Snowplow Unified Digital package that produces a users table.
We provide user stitching on one layer: between the primary user_identifier field and a custom defined (var('snowplow__user_stitching_id')) id field. The package considers the user_identifier field as the primary key for the users table and this would typically be the most "reliable" cookie based field, hence it is defaulted to domain_userid when processing web events and the session_context entity based user_id for mobile events. The custom defined id to be used for stitching is recommended to be the atomic.user_id field that is used for tracking logged in users. This reliable user identifier field is the common denominator for applying the so called session-stitching in our packages.
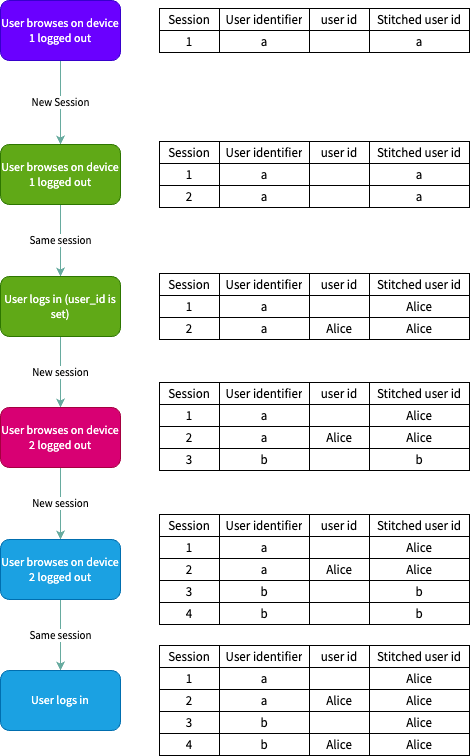
This works by having an User Mapping table that collects and incrementally updates the latest official logged in user_id field for all user_identifiers processed in the current run (taken from the event_this_run table). This mapping is then applied to the derived tables (e.g views table if snowplow__view_stitching is enabled and both the sessions and users table if snowplow__session_stitching is enabled). The update is carried out by a post-hook (defined in the config of each derived incremental table), which updates the stitched_user_id column with the latest mapping. If no mapping is present, the default value for stitched_user_id is the user identifier itself. This process is known as session stitching, and effectively allows you to attribute logged-in and non-logged-in sessions back to a single user.
Cross platform stitching
The snowplow_unified package means that all the user data, from both web and mobile, is modeled in one place. This makes it easy to effectively perform cross-platform stitching, which means that as soon as a users identify themselves by logging in as the same user on separate platforms, all the user data will be found within one package making it convenient for performing further analysis. We encourage everyone to take the base stitching logic provided by the package further by applying a custom aggregation downstream layer that takes the first/last fields per stitched_user_id from the users table as well a applying additional stitching based on custom user_mapping table(s) depending on need.
In order for the user_mapping table to successfully update the stitched_user_id field in the users table, it needs to stay unique on session_identifier which means that if for some reason there are multiple user_ids per user_identifier, we take the latest one. For a standard use case when the user_identifier is a cookie based domain_userid and the user_stitching_id is the logged in atomic.user_id field, we encourage everyone to remove cookies to force creating a new session upon the user log out action to avoid a scenario when multiple users log in and out quickly after one another on the same device (e.g. school, library). For tracking advice, have a look at this documentation.


If required, this update operation can be disabled by setting in your dbt_project.yml file (selecting one of web/mobile, or both, as appropriate):
vars:
snowplow_<package>:
snowplow__session_stitching: false
Consider processing costs before enabling snowplow__view_stitching to true. It may be enough to apply this with less frequency than on sessions to keep costs down, by only enabling this at runtime on only some of the runs.
Custom solutions
Customizing user identifiers
Customizing user identifiers works in the exact same way as customizing session identifiers, please refer to that link to understand the breakdown of how to set this up, although you need to make use of the snowplow__user_identifiers variable instead of the snowplow__session_identifiers, and snowplow__user_sql in place of snowplow__session_sql.
vars:
snowplow_unified:
# This is an example of user identifiers for BigQuery
snowplow__user_identifiers: [{"schema": "contexts_com_snowplowanalytics_user_identifier_2_*", "field" : "user_id"}, {"schema": "contexts_com_snowplowanalytics_user_identifier_1_*", "field" : "user_id"}]
# For Databricks
snowplow__user_identifiers: [{"schema": "contexts_com_snowplowanalytics_user_identifier_2", "field" : "user_id"}, {"schema": "contexts_com_snowplowanalytics_user_identifier_1", "field" : "user_id"}]
# For Redshift/Postgres
snowplow__user_identifiers: [{"schema": "contexts_com_snowplowanalytics_user_identifier_2", "field" : "user_id", "prefix" : "ui_t", "alias": "uidt"}, {"schema": "contexts_com_snowplowanalytics_user_identifier_1", "field" : "user_id", "prefix": "ui_o", "alias": "uido"}]
# For Snowflake
snowplow__user_identifiers: [{"schema": "contexts_com_snowplowanalytics_user_identifier_2", "field" : "userId"}, {"schema": "contexts_com_snowplowanalytics_user_identifier_1", "field" : "userId"}]
If you need a specific way to refer to a custom user you can also use the snowplow_user_sql variable, which will override any default or overwrites on snowplow__user_identifiers.
Please note, however, that the snowplow__user_identifiers variable is not designed to handle user stitching the way you might expect it. Currently, there is a limitation that if any of the identifiers in the list do not persist throughout the session, there is no guarantee that the highest-prestige identifier (first in the list) will take precedence.
This is particularly relevant for those adding user_id as the first element in their list, as it may be NULL for some events within a session. For that it is best to rely on the package based user stitching logic, leave user_id as the snowplow__user_stitching_id and rely on the stitched_user_id field produced by the package in each derived tables as the main identifier field. This way even if the user logged in for some period of the time within a session the user_id field will be found and prioritized over the rest.
Alternatively, to ensure a deterministic user selection, you could rely on the snowplow_user_sql variable instead to something like this:
COALESCE(
MAX(user_id),
MAX(domain_userid),
MAX(network_userid)
) OVER (PARTITION BY session_identifier)
This ensures that MAX(user_id) is computed separately before applying COALESCE() at the session level, preventing another identifier from accidentally taking precedence.
Handling Anonymized Users
In case of applying Client-side anonymization with session tracking, the userId property of the contexts_com_snowplowanalytics_snowplow_client_session_1 equates to a null UUID which will appear as 00000000-0000-0000-0000-000000000000 in the database. It may be convenient to make this field an actual NULL field to make it easier to exclude them from modeling (e.g the user mapping table of the Unified Package excludes null values). This can be made possible with the use of the snowplow__user_sql variable, however, this means that the extraction from the relevant context/sde field needs to be handled manually.
Example implementation (Snowflake):
vars:
snowplow_unified:
snowplow__user_sql: 'coalesce(case when contexts_com_snowplowanalytics_snowplow_client_session_1[0]:userId::varchar(36) == "00000000-0000-0000-0000-000000000000" then null else contexts_com_snowplowanalytics_snowplow_client_session_1[0]:userId::varchar(36) end, domain_userid)'
Defining the snowplow__user_sql variable will ensure that the package takes its value as the user_identifier over anything you may have defined with the snowplow__user_identifiers variable.
User mapping is typically not a one-size-fits-all exercise. Depending on your tracking implementation, business needs and desired level of sophistication you may want to write bespoke logic. Please refer to this blog post for ideas. The unified package offer the ability to change what field is used as your stitched user id, so instead of user_id you can use any field you wish (note that it will still be called user_id in your mapping table), and by taking advantage of the custom sessionization and users you can also change the field used as the user_identifier (unified model).
Overview
The below diagram shows a potential flow your user may take across multiple devices. It does not matter if they are web or mobile events as Unified will correctly process and stitch both. As the user progresses through the (simplified) sessions table tracks their sessions, user identifier, user ID, and stitched user id. Once a user ID is identifier for specific user identifier it is backdated in the stitched column for all sessions with that identifier. Note that this is not possible until the user logs in during a session.