BigQuery Loader (0.5.x)
Technical Architecture
The available tools are:
- Snowplow BigQuery Loader, an Apache Beam job that reads Snowplow enriched data from Google Pub/Sub, transforms it into BigQuery-friendly format and loads it. It also writes information about encountered data types into an auxiliary
typesTopicPub/Sub topic. - Snowplow BigQuery Mutator, a Scala app that reads the
typesTopic(viatypesSubscription) and performs table mutations to add new columns as required. - Snowplow BigQuery Repeater, a Scala app that reads
failedInserts(caused by mutation lag) and tries to re-insert them into BigQuery after some delay, sinking failures into a dead-end bucket. - [DEPRECATED] Snowplow BigQuery Forwarder, an alternative to Repeater implemented as an Apache Beam job. This component has been deprecated from version 0.5.0. Please use Repeater instead.
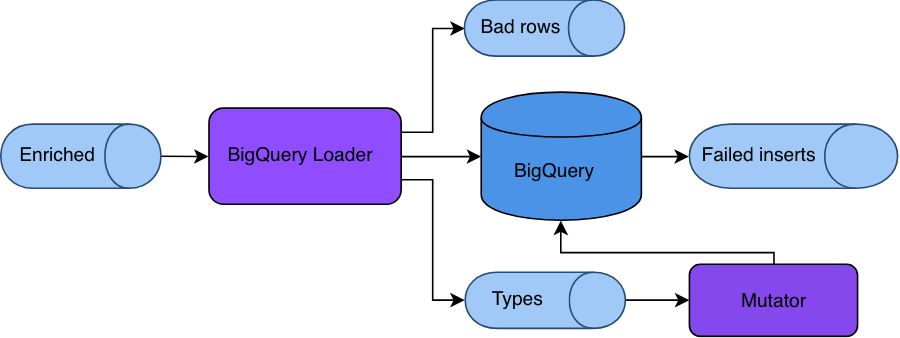
In addition it also includes a fourth microservice, the "repeater".
Snowplow BigQuery Loader
Overview
An Apache Beam job intended to run on Google Dataflow and load enriched data from enriched Pub/Sub topic to Google BigQuery.
Algorithm
- Reads Snowplow enriched events from
inputPub/Sub subscription. - Uses the JSON transformer from the Snowplow Scala Analytics SDK to convert those enriched events into JSONs.
- Uses Iglu Client to fetch JSON schemas for self-describing events and entities.
- Uses Iglu Schema DDL to transform self-describing events and entities into BigQuery format.
- Writes transformed data into BigQuery.
- Writes all encountered Iglu types into a
typesTopic. - Writes all data failed to be processed into a
badRowstopic. - Writes data that succeeded to be transformed, but failed to be loaded into a
failedInsertstopic.
Snowplow BigQuery Mutator
Overview
This is a Scala app that reads data from the typesTopic via a typesSubscription and performs table mutations.
Algorithm
- Reads messages from
typesSubscription. - Finds out if a message contains a type that has not been encountered yet (by checking internal cache).
- If a message contains a new type, double-checks it with the connected BigQuery table.
- If the type is not in the table, fetches its JSON schema from Iglu Registry.
- Transforms JSON schema into BigQuery column definition.
- Adds the column to the connected BigQuery table.
Snowplow BigQuery Repeater
A JVM application that reads a failedInserts subscription and tries to re-insert them into BigQuery to overcome mutation lag.
Overview
Repeater has several important behavioral aspects:
- If a pulled record is not a valid Snowplow event, it will result into a
loader_recovery_errorbad row. - If a pulled record is a valid event, Repeater will wait some time (5 minutes by default) after the
etl_tstampbefore attempting to re-insert it, in order to let Mutator do its job. - If the database responds with an error, the row will get transformed into a
loader_recovery_errorbad row. - All entities in the dead-end bucket are valid Snowplow bad rows.
Mutation lag
Loader inserts data into BigQuery in near real-time. At the same time, it sinks shredded_type payloads into the typesTopic approximately every 5 seconds. It also can take up to 10-15 seconds for Mutator to fetch, parse the message and execute an ALTER TABLE statement against the table.
If a new type arrives from input subscription in this period of time and Mutator fails to handle it, BigQuery will reject the row containing it and it will be sent to the failedInserts topic. This topic contains JSON objects ready to be loaded into BigQuery (ie not canonical Snowplow Enriched event format).
In order to load this data again from failedInserts to BigQuery you can use Repeater or Forwarder (see below). Both read a subscription from failedInserts and perform INSERT statements.
[DEPRECATED] Snowplow BigQuery Forwarder
This component has been deprecated from version 0.5.0. Please use Repeater instead. The documentation on Forwarder that follows is outdated and no longer maintained. It will be removed in future versions.
Used for exactly the same purpose as Repeater, but uses Dataflow under the hood, which makes it suitable for very big amounts of data. At the same time, it has several important drawbacks compared with Repeater:
- User needs to re-launch it manually when failed inserts appear.
- Otherwise, it could be extremely expensive to run a Dataflow job that idles 99.9% of the time (it cannot terminate as it is a streaming/infinite job1).
- There's no way to tell Forwarder that it should take a pause before inserting rows back. Without the pause there's a chance that Mutator doesn't get a chance to alter the table.
- Forwarder keeps retrying all inserts (default behavior for streaming Dataflow jobs), while Repeater has a dead-end GCS bucket.
- In order to debug a problem with Forwarder, operator needs to inspect Stackdriver logs.
1Forwarder is a very generic and primitive Dataflow job. It could be launched using the standard Dataflow templates. But a standard template job cannot accept a subscription as a source, only a topic. That means the job must be running all the time and most of the time it will be idle.
Topics and message formats
Snowplow BigQuery Loader uses Google Pub/Sub topics and subscriptions to store intermediate data and communicate between applications.
inputsubscription -- data enriched by Beam Enrich, in canonicalTSV+JSON format;typesTopic-- all shredded types iniglu:com.snowplowanalytics.snowplow/shredded_type/jsonschema/1-0-0self-describing payload encountered by Loader are sinked here with ~5 seconds interval;typesSubscription-- a subscription totypesTopicused by Mutator withiglu:com.snowplowanalytics.snowplow/shredded_type/jsonschema/1-0-0self-describing payloads;badRowstopic -- data that could not be processed by Loader due to Iglu Registry unavailability, formatted asbad rows;failedInsertstopic -- data that has been successfully transformed by Loader, but failed loading to BigQuery usually due to mutation lag, formatted asBigQuery JSON.
Setup guide
Configuration file
Loader, Mutator and Repeater (Forwarder has been deprecated) accept the same configuration file with iglu:com.snowplowanalytics.snowplow.storage/bigquery_config/jsonschema/ schema, which looks like this:
{
"schema": "iglu:com.snowplowanalytics.snowplow.storage/bigquery_config/jsonschema/1-0-0",
"data": {
"name": "Alpha BigQuery test",
"id": "31b1559d-d319-4023-aaae-97698238d808",
"projectId": "com-acme",
"datasetId": "snowplow",
"tableId": "events",
"input": "enriched-good-sub",
"typesTopic": "bq-test-types",
"typesSubscription": "bq-test-types-sub",
"badRows": "bq-test-bad-rows",
"failedInserts": "bq-test-bad-inserts",
"load": {
"mode": "STREAMING_INSERTS",
"retry": false
},
"purpose": "ENRICHED_EVENTS"
}
}
- All topics and subscriptions (
input,typesTopic,typesSubscription,badRowsandfailedInserts) are explained in the topics and message formats section. projectIdis used to group all resources (topics, subscriptions and BigQuery table).datasetIdandtableId� (along withprojectId) specify the target BigQuery table.nameis an arbitrary human-readable description of the storage target.idis a unique identificator in UUID format.loadspecifies the loading mode and is explained in the dedicated section below.purposeis a standard storage configuration. Its only valid value currently isENRICHED_EVENTS.
Loading mode
BigQuery supports two loading APIs:
You can use the load property to configure Loader to use one of them.
For example, the configuration for using streaming inserts can look like this:
{
"load": {
"mode": "STREAMING_INSERTS",
"retry": false
}
}
retry specifies if failed inserts (eg due to mutation lag) should be retried infinitely or sent straight to the failedInserts topic. If a row cannot be inserted, it will be re-tried indefinitely, which can throttle the whole job. In that case a restart might be required.
The configuration for using load jobs can look like this:
{
"load": {
"mode": "FILE_LOADS",
"frequency": 60000
}
}
frequency specifies how often the load job should be performed, in seconds. Unlike the near-real-time streaming inserts API, load jobs are more batch-oriented.
Load jobs do not support retry (and streaming inserts do not support frequency).
It is generally recommended to stick with the streaming jobs API without retries and use Repeater to recover data from failedInserts. However, the load jobs API is cheaper and generates fewer duplicates.
Command line options
All four apps accept a path to a config file as specified above, and to an Iglu resolver config.
Loader
Loader accepts two required arguments, one optional argument, and any other supported by Google Cloud Dataflow.
$ ./snowplow-bigquery-loader \
--config=$CONFIG \
--resolver=$RESOLVER
--labels={"key1":"val1","key2":"val2"} # optional
The optional labels argument is an example of a Dataflow natively supported argument. It accepts a JSON with key-value pairs that will be used as labels to the Cloud Dataflow job.
This can be launched from any machine authenticated to submit Dataflow jobs.
Mutator
Mutator has three subcommands: listen, create and add-column.
listen
listen is the primary command and is used to automate table migrations.
$ ./snowplow-bigquery-mutator \
listen
--config $CONFIG \
--resolver $RESOLVER \
--verbose # Optional, for debugging only
add-column
add-column can be used once to add a column manually. This should eliminate the risk of mutation lag and the necessity to run a Repeater or Forwarder job.
$ ./snowplow-bigquery-mutator \
add-column \
--config $CONFIG \
--resolver $RESOLVER \
--shred-property CONTEXTS \ --schema iglu:com.acme/app_context/jsonschema/1-0-0
The specified schema must be present in one of the Iglu registries in the resolver configuration.
create
create creates an empty table with atomic structure.
$ ./snowplow-bigquery-mutator \
create \
--config $CONFIG \
--resolver $RESOLVER
Repeater
We recommend constantly running Repeater on a small / cheap node or Docker container.
$ ./snowplow-bigquery-repeater \
create \
--config $CONFIG \
--resolver $RESOLVER \
--failedInsertsSub $FAILED_INSERTS_SUB \
--deadEndBucket $DEAD_END_GCS \ # Must start with gcs:\\ prefix
--desperatesBufferSize 20 \ # Size of the batch to send to the dead-end bucket
--desperatesWindow 20 \ # Window duration after which bad rows will be sunk into the dead-end bucket
--backoffPeriod 900 # Seconds to wait before attempting a re-insert (calculated against etl_tstamp)
desperatesBufferSize, desperatesWindow and backoffPeriod are optional parameters.
[DEPRECATED] Forwarder
This component has been deprecated from version 0.5.0. Please use Repeater instead. The documentation on Forwarder that follows is outdated and no longer maintained. It will be removed in future versions.
Like Loader, Forwarder can be submitted from any machine authenticated to submit Dataflow jobs.
$ ./snowplow-bigquery-forwarder \
--config=$CONFIG \
--resolver=$RESOLVER
--labels={"key1":"val1","key2":"val2"} # optional
--failedInsertsSub=$FAILED_INSERTS_SUB
Its only unique option is failedInsertsSub, which is a subscription (that must be created upfront) to the failedInserts topic.
The labels argument works the same as with Loader.
By convention both Dataflow jobs (Forwarder and Loader) accept CLI options with = symbol and camelCase, while Mutator and Repeater accept them in UNIX style (without =).
Docker support
All four applications are available as Docker images.
snowplow/snowplow-bigquery-loader:0.5.0snowplow/snowplow-bigquery-mutator:0.5.0snowplow/snowplow-bigquery-repeater:0.5.0snowplow/snowplow-bigquery-forwarder:0.5.0
Partitioning
During initial setup it is strongly recommended to setup partitioning on the derived_tstamp property. Mutator's create command does not automatically add partitioning yet.