Managing data quality
Failed events are events the pipeline had some problem processing. Snowplow pipelines separate events that are problematic in order to keep data quality high in downstream systems.
We provide tooling for monitoring, loading, and recovering failed events.
Snowplow offers two different ways to monitor failed events in Snowplow Console:
- The data quality dashboard that surfaces failed events directly from your warehouse in a secure manner, making debugging easier
- The default view
You can also use the Console API to monitor failed events.
Monitoring dashboard comparison#
The data quality dashboard and the default view are both useful in monitoring for failed events. Which one to choose depends on your requirements. This table summarises the differences:
| Feature | Data quality dashboard | Default view |
|---|---|---|
| Requirements | Deployed Failed Events Loader | No additional infrastructure needed |
| Detail provided | Complete failed events JSON | Aggregated data with redacted error messages |
| PII security | Data never leaves your infrastructure | Redacted data flows through Snowplow systems |
| Warehouse support | Snowflake and BigQuery only | All warehouses |
Data quality dashboard#
The data quality dashboard allows you to see failed events directly from your warehouse. Your browser connects directly to an API running within your infrastructure, such that no failed event information flows through Snowplow. The discussion of architecture is important as it highlights the trade-offs between the two ways of monitoring failed events. The aforementioned API is a simple proxy that connects to your warehouse and serves the failed events to your browser. The connection is fully secure, using an encrypted channel (HTTPS) and authenticating/authorizing via the same mechanism used by Console.
In order for you to be able to deploy and use the data quality dashboard, you need to sink failed events to the warehouse via a Failed Events Loader. The data quality dashboard currently supports Snowflake and Bigquery connections.
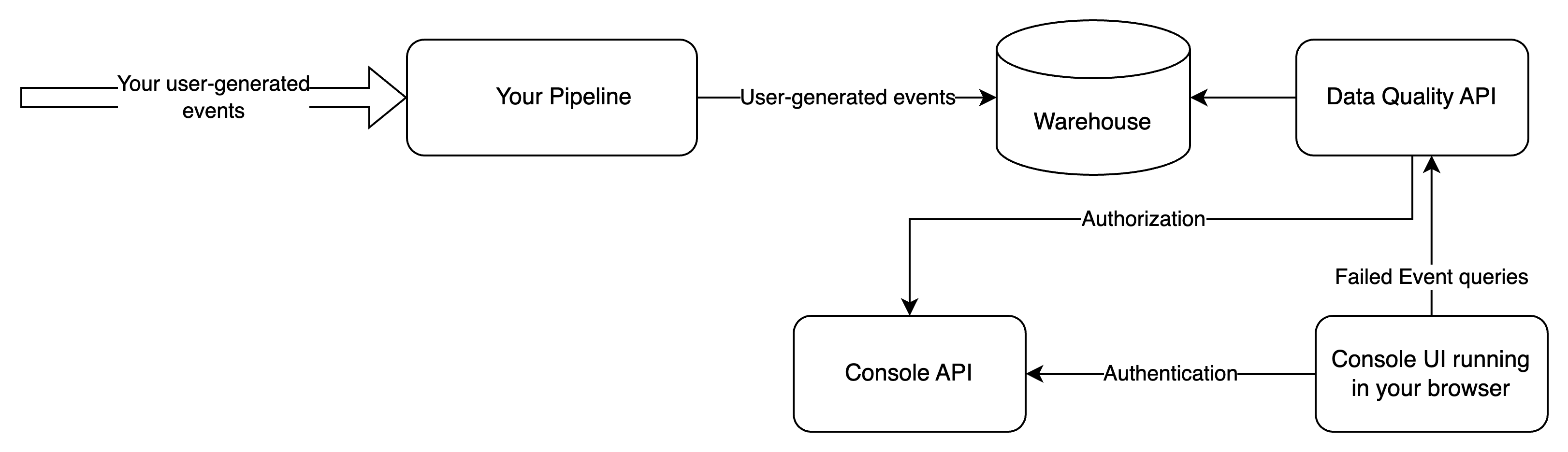
In this setup, you expose an additional interface (Data Quality API) to the public internet, and all failed events information is served via that interface.
The user experience of the data quality dashboard is similar to the default view, but offers substantially more information to support resolution of tracking issues. The overview page looks as follows:
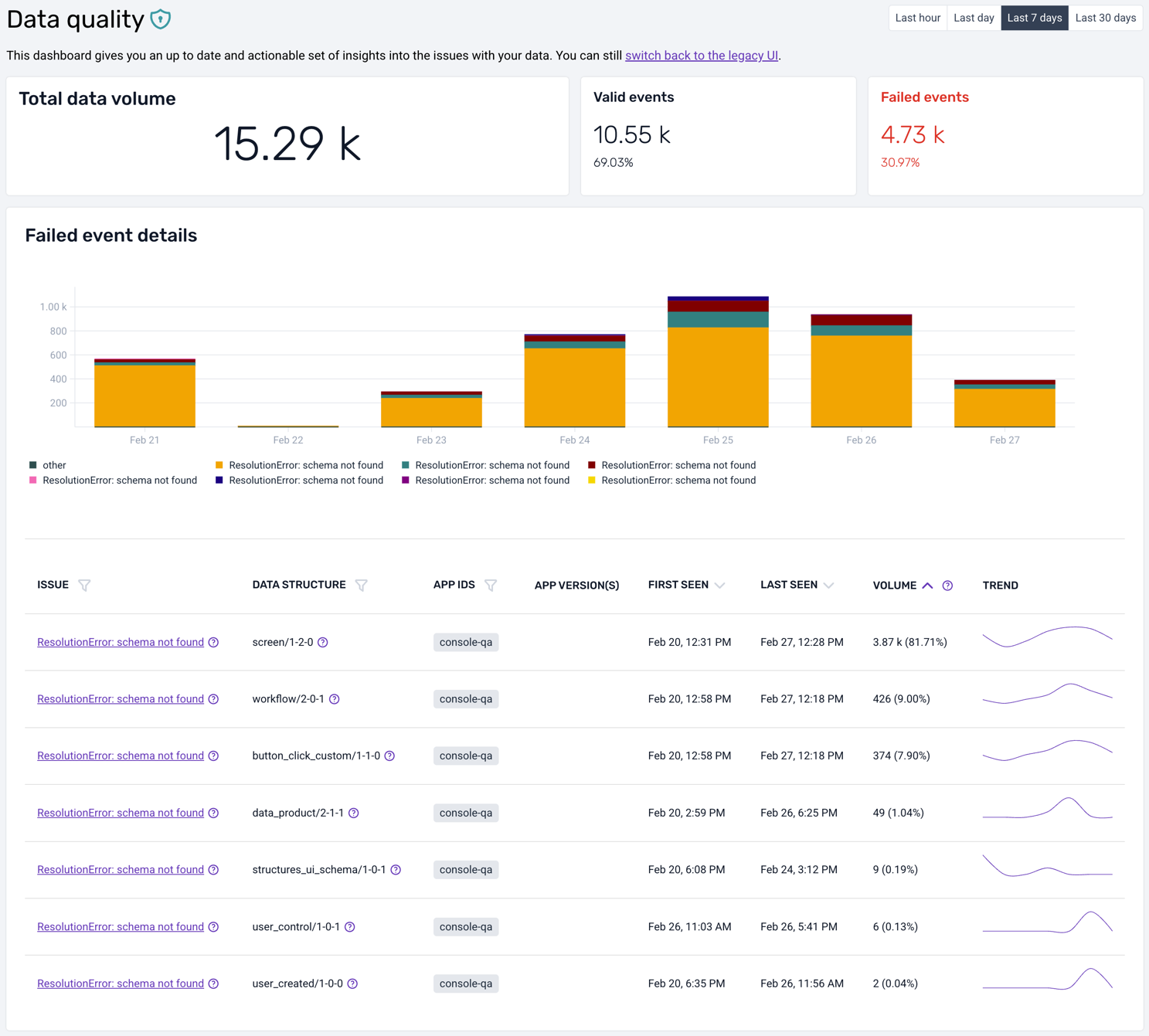
As in the default view, it is possible to change the time horizon from the 7-day default, to the last hour, last day, or last 30 days. You get a corresponding overview of event volumes, both the successful and the failed ones, for the whole time period but also split per day/hour/minute in the bar chart right below.
Complementing the graphical overview, there is a table that lists all errors (at this moment only validation and resolution errors are supported). You can quickly see, for each type of failed event, a short description of the root cause, the offending data structure, first and last seen timestamps, and the total volume.
Clicking on a particular error type will take you to a detailed view:
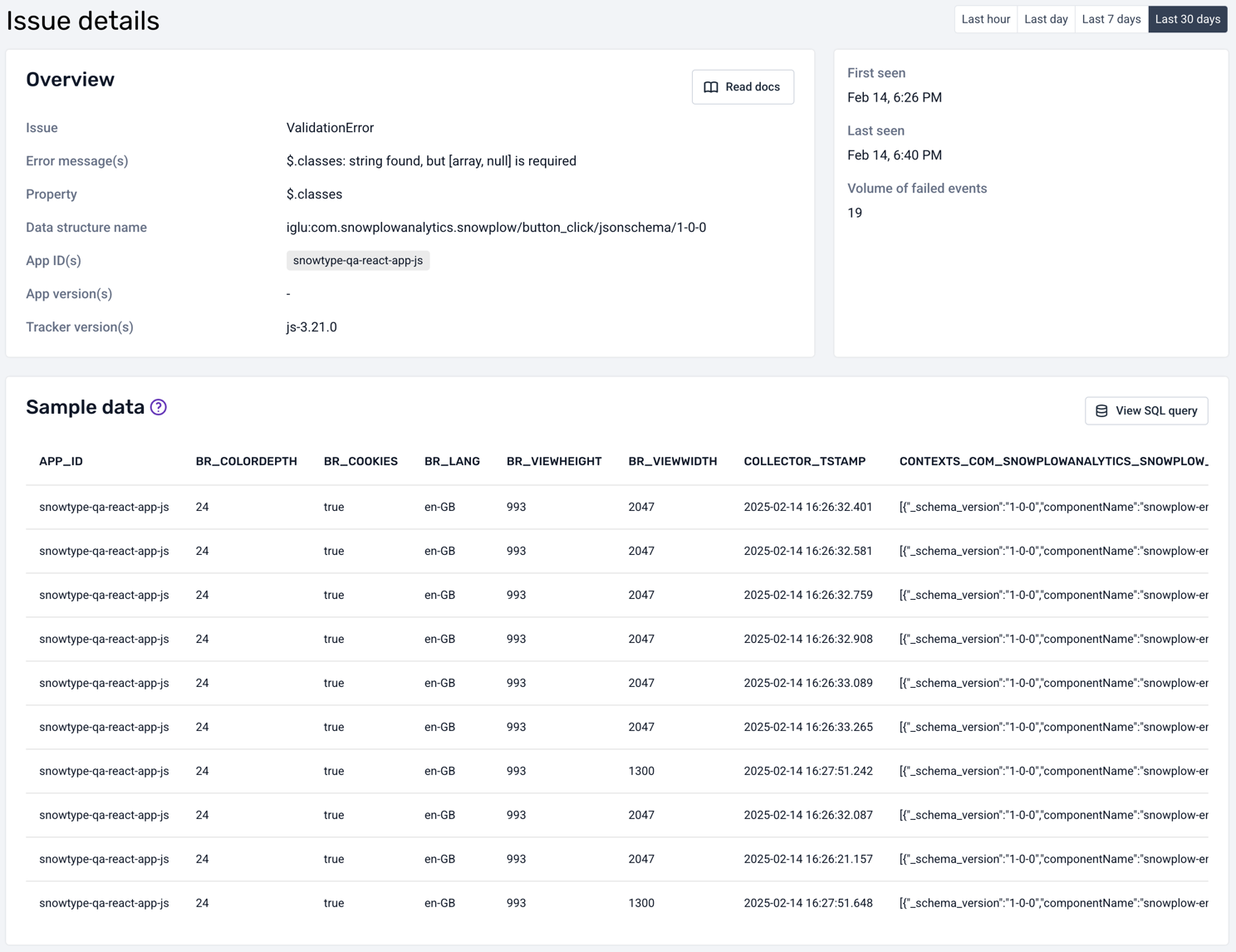
The detailed view also shows a description of the root cause and the application version (web, mobile). It provides a sample of the failed events in their entirety, as found in your warehouse.
Some columns are too wide to fit in the table: click on them to see the full pretty-printed, syntax-highlighted content. The most useful column to explore is probably CONTEXTS_COM_SNOWPLOWANALYTICS_SNOWPLOW_FAILURE_1, which contains the actual error information encoded as a JSON object:
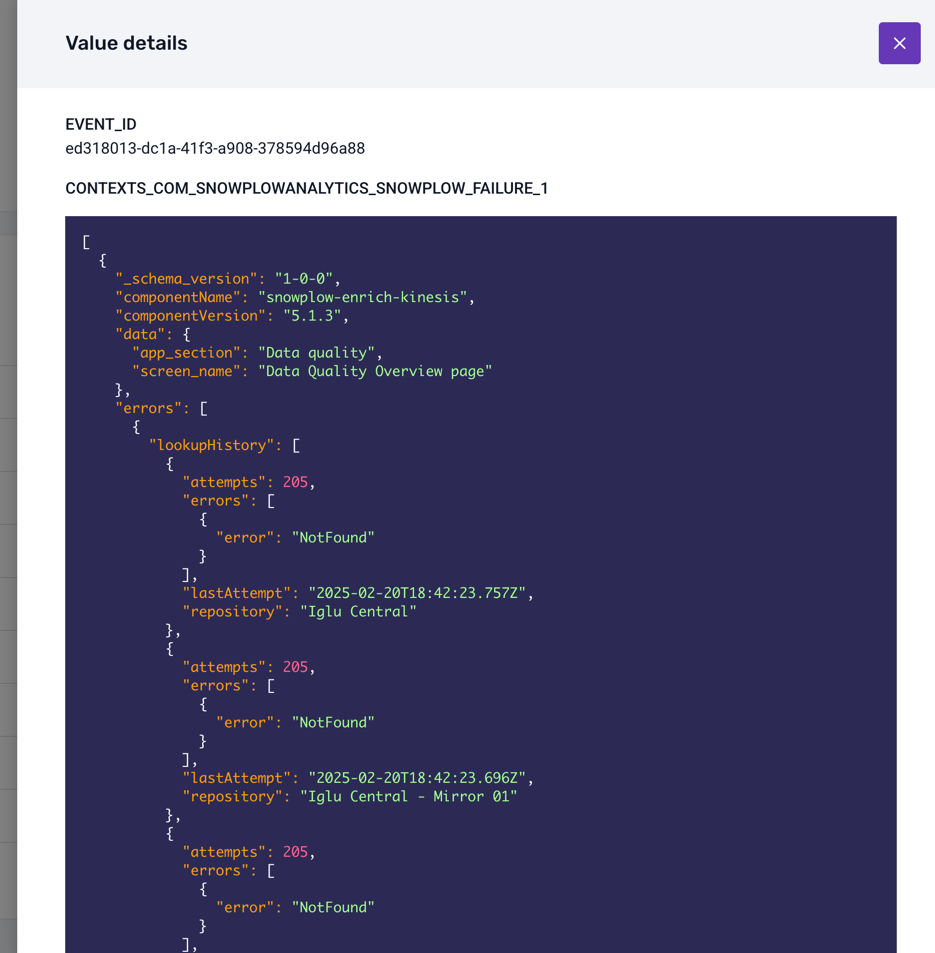
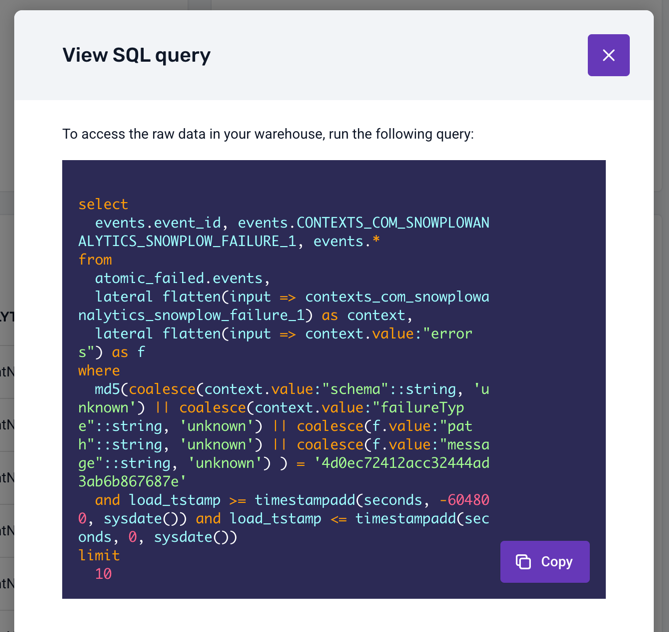
Finally, you can click on the View SQL query button to see the SQL query that was used to fetch the failed events from your warehouse:
Missing warehouse permissions#
When deploying a loader with the data quality add-on (API), you may encounter permission errors that prevent the dashboard from querying your warehouse.
- BigQuery
- Snowflake
If your service account lacks the required permission to create BigQuery jobs, you may receive the following error:
- Error code:
21xxx - Description:
Missing permission 'bigquery.jobs.create' on Bigquery...
Check if your service account has the required role:
gcloud projects get-iam-policy <PROJECT_ID> \
--flatten="bindings[].members" \
--filter="bindings.members:<SERVICE_ACCOUNT_EMAIL>" \
--format="table(bindings.role)"
To fix the error, grant the required role to your service account (recommended):
gcloud projects add-iam-policy-binding <PROJECT_ID> \
--member="serviceAccount:<SERVICE_ACCOUNT_EMAIL>" \
--role="roles/bigquery.jobUser"
Alternatively, if you need more granular control, create a custom role with only the bigquery.jobs.create permission:
gcloud iam roles create customBigQueryJobCreator \
--project=<PROJECT_ID> \
--title="BigQuery Job Creator" \
--description="Create BigQuery jobs for Data Quality Dashboard" \
--permissions="bigquery.jobs.create"
gcloud projects add-iam-policy-binding <PROJECT_ID> \
--member="serviceAccount:<SERVICE_ACCOUNT_EMAIL>" \
--role="projects/<PROJECT_ID>/roles/customBigQueryJobCreator"
If your role lacks USAGE privilege on the active warehouse, queries cannot be performed. You may receive the following error:
- Error code:
11xxx - Description:
Missing required privileges on Snowflake: No active warehouse selected in the current session...
Verify current warehouse privileges for your role:
SHOW GRANTS ON WAREHOUSE <WAREHOUSE_NAME>;
SHOW GRANTS TO ROLE <ROLE_NAME>;
If necessary, grant the USAGE privilege on the warehouse:
GRANT USAGE ON WAREHOUSE <WAREHOUSE_NAME> TO ROLE <ROLE_NAME>;
Ensure the grant is properly applied:
-- Verify the grant
SHOW GRANTS ON WAREHOUSE <WAREHOUSE_NAME>;
Query timeouts#
Long-running queries, a large volume of failed events, or resource pool exhaustion can cause the data quality dashboard to time out when fetching failed events. You may receive the following errors:
- Error codes:
12xxxor22xxx - Description:
Query exceeded timeoutorQuery execution time limit exceeded
- BigQuery
- Snowflake
Diagnose the cause of the error by running:
-- Check recent query performance
SELECT
job_id,
user_email,
total_slot_ms,
total_bytes_processed,
TIMESTAMP_DIFF(end_time, start_time, SECOND) as duration_seconds
FROM `<PROJECT_ID>.region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
AND state = 'DONE'
AND statement_type = 'SELECT'
ORDER BY total_slot_ms DESC
LIMIT 10;
Diagnose the cause of the error by running:
-- Check query history
SELECT
query_id,
query_text,
warehouse_name,
execution_time,
queued_overload_time,
bytes_scanned
FROM table(information_schema.query_history())
WHERE start_time >= DATEADD('day', -1, CURRENT_TIMESTAMP())
AND execution_status = 'SUCCESS'
ORDER BY execution_time DESC
LIMIT 10;
To fix these errors, try:
- Reducing query scope
- For Console, try switching to using legacy failed events based on telemetry data
- If using the API, try using smaller time windows, e.g., "Last hour" or "Last day" instead of "Last 30 days"
- Query specific error types or schemas rather than all failed events
- Optimizing warehouse performance
- Review your warehouse configuration and query patterns
- Consider implementing partitioning, clustering, or other optimization strategies
- Monitor resource usage, and adjust warehouse size as needed
Default view#
The default view is a relatively simple interface that shows the number of failed events over time alongside a coarse-grained description of the problem at hand. In certain cases, the error message can be somewhat cryptic in terms of diagnosing the root cause of the error. The reason is that this information flows through Snowplow infrastructure, therefore we have redacted it substantially before it leaves your pipeline, to ensure that PII does not traverse Snowplow systems. The aggregates are served by the Console's backend:
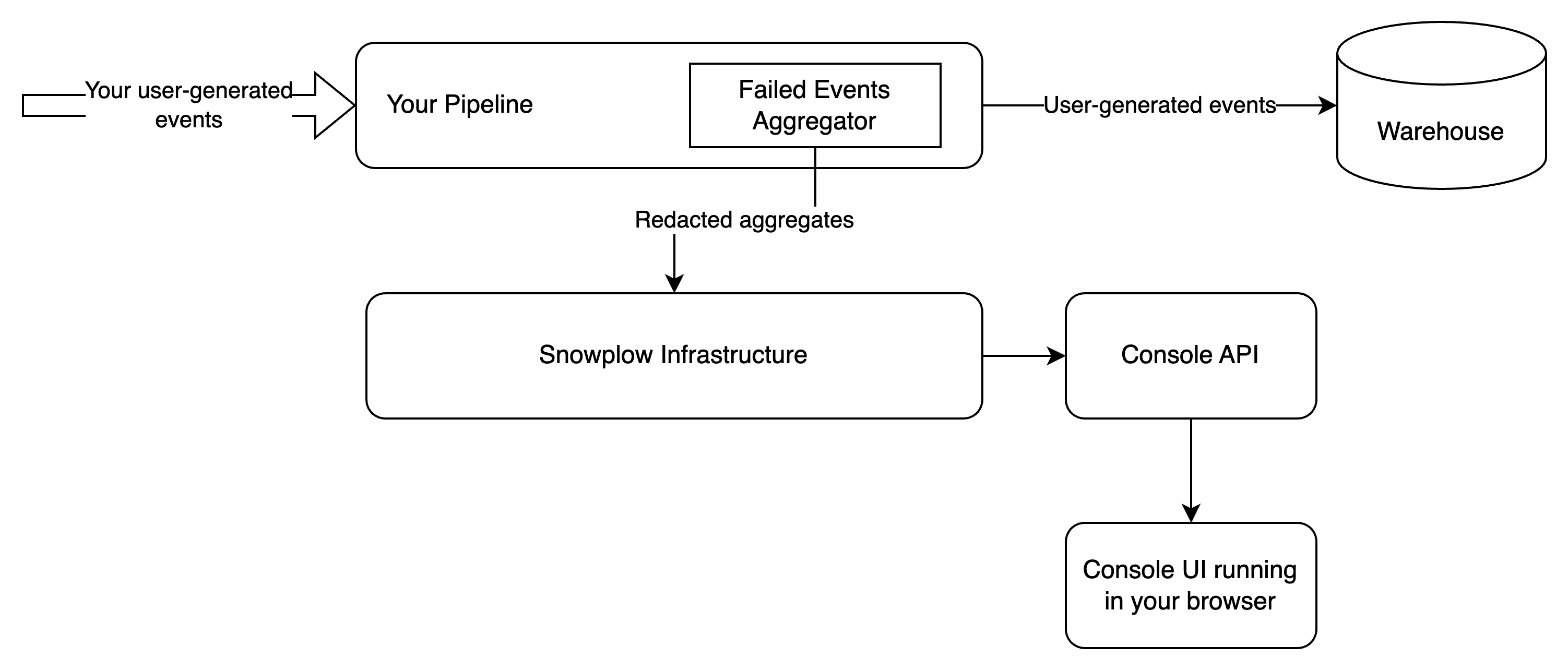
In this setup, you expose no additional interface to the public internet, and all failed events information is served by the Console's APIs.
Below is an example view of the failed events screen in Snowplow Console:
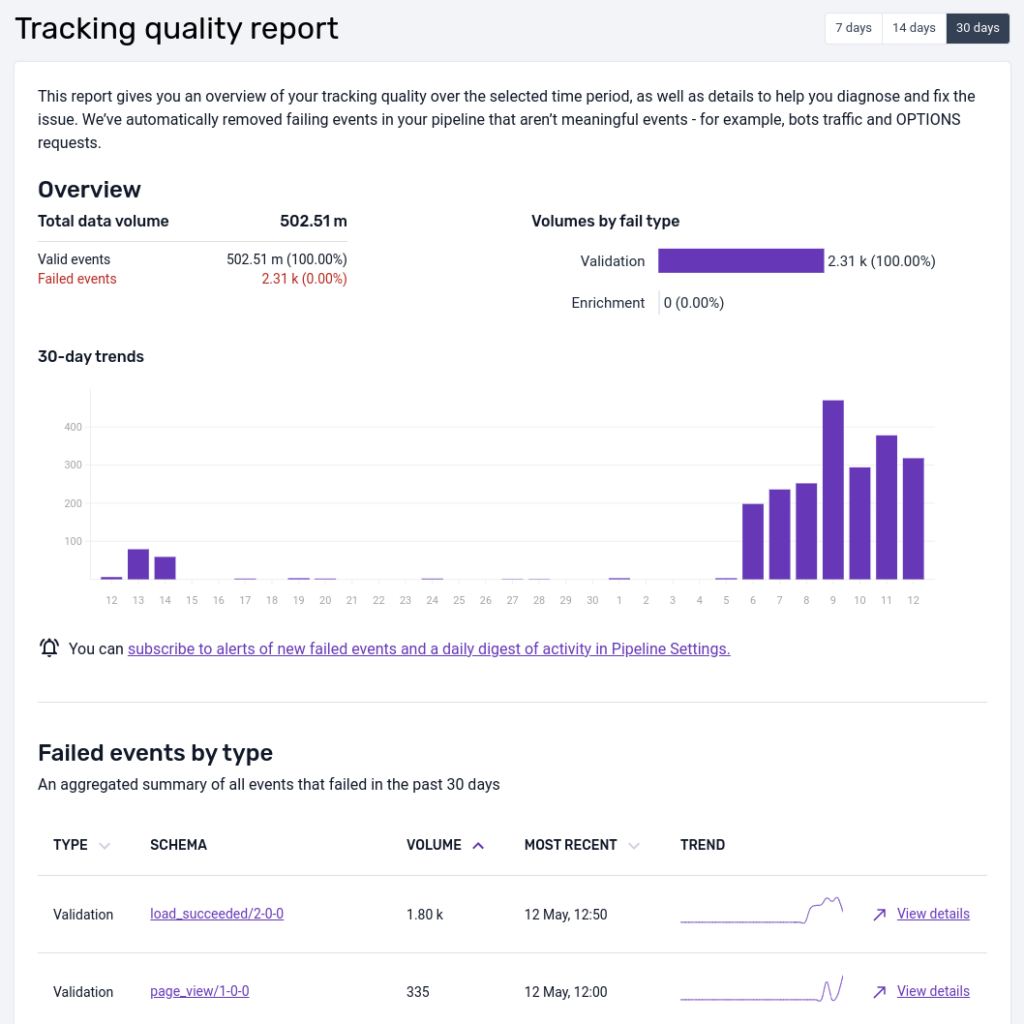
This interface is intended to give you a quick representation of the volume of event failures so that action can be taken. The UI focuses on schema violation and enrichment errors at present.
We've filtered on these two types of errors to reduce noise like bot traffic that causes adapter failures for instance. All failed events can be found in your S3 or GCS storage targets partitioned by type and then date/time.
At the top there is a data quality score that compares the volume of failed events to the volume that were successfully loaded into a data warehouse.
The bar chart shows how the total number of failed events varies over time, color-coding validation and enrichment errors. The time window is 7 days be default but can be extended to 14 or 30 days.
In the table, failed events are aggregated by the unique type of failure (validation, enrichment) and the offending schema.
By selecting a particular error you are able to get more detail:
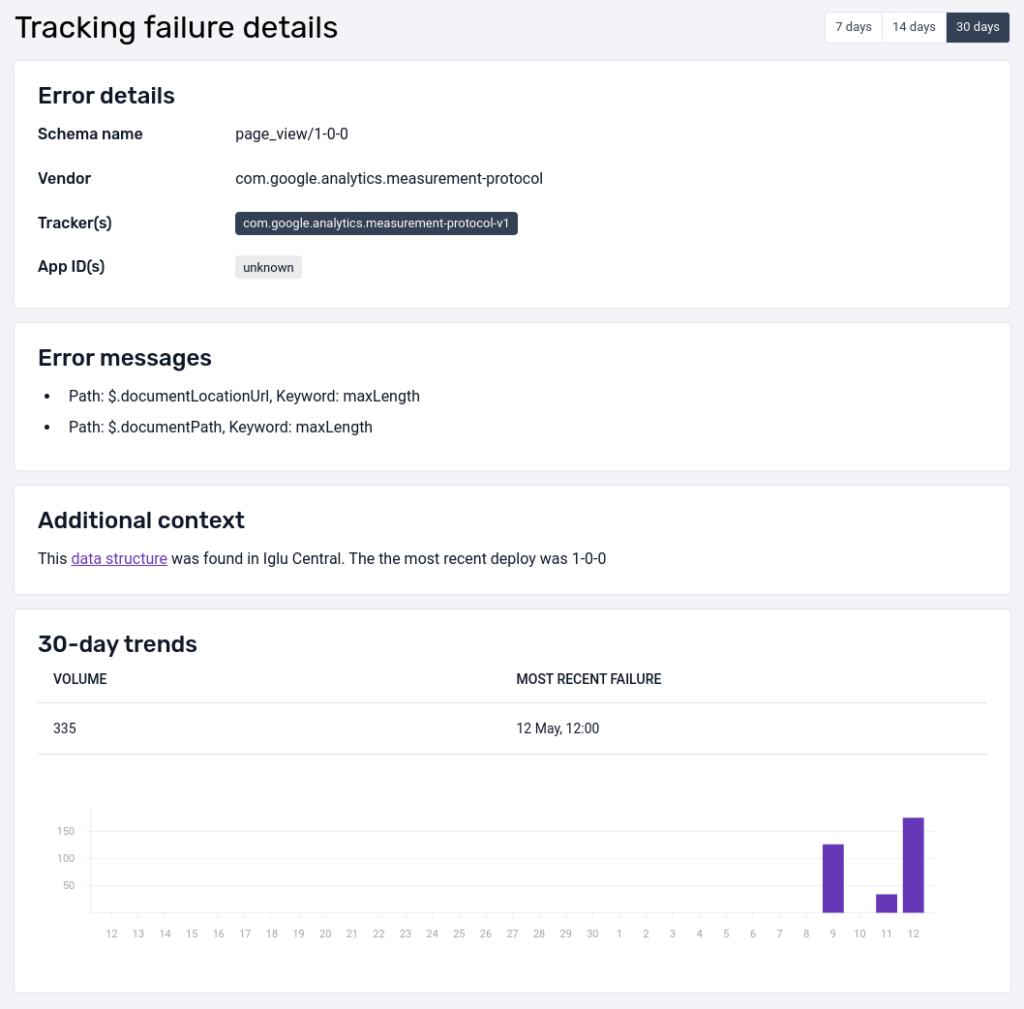
The detailed view shows the error message as well as other useful metadata (when available), like app_id, to help diagnose the source and root cause of the error; as well as a bar chart indicating how the volume of failures varies over time for this particular failed event.
Console API#
The API that powers the Console view and dashboard is publicly available, and can be invoked with a valid token to feed your own monitoring systems.
Before you can invoke the Failed Events API, you will need to authenticate with an API key.
A full specification of the API can be found in our swagger docs. It is worth pointing out that, as is the case in the UI, the data returned only contains schema validation errors and enrichment failures.