Recovering failed events with SQL
This guide will walk you through the process of recovering failed events from your failed events table back into your good events table. Failed events occur when events don't pass validation during processing, typically due to schema violations or enrichment failures.
Recovery process
Recovering failed events involves identifying the failure type, reconstructing the data, and reinserting it into your good events table. The process varies depending on the specific failure that occurred.
The main steps are:
- Identify the type of failure: there are many possible reasons an event can fail and end up in your failed events table. The failed events table only includes schema violations and enrichment failures, but there are still many different types:
- Missing schema - the schema referenced (or specific version of that schema) isn't present in your prod Iglu repository.
- Missing required property.
- Extra properties that are not allowed in this schema version.
- Referencing an incorrect schema version.
- Incorrect data type.
- Breaching a validation rule (a
min,max,minLength,maxLength,pattern,format,enum, etc.)
- Reconstruct the offending row: how you do this will depend on the type of failure that has occurred, and your specific business logic. For example, if you have a missing schema, because you started tracking before pushing the schema to Prod, then you should push the schema to Prod, and then essentially just select the values from the failure entity. However, if you have a string that is too long for the
maxLengthvalidation rule for example, then you must choose how to resolve this (trim to the max allowed value, or push a new schema with an increased limit, and change the schema version in the offending row from the original to the new version). - Create a prep
SELECTstatement: create a statement that addresses the issue. You can test this by attempting toUNIONyour prep table to aSELECTfrom the goodeventstable to check for type inconsistencies. - Create an
INSERTcommand: add the repaired row back to the maineventstable, leaving all other values unaltered. You can either type this out by hand, or if you don't want to do this (your events table may have hundreds of columns which is time consuming and error prone to type out manually) you can use theINFORMATION_SCHEMA.COLUMNSmetadata table in your warehouse to construct theINSERTcommand programmatically.
Identifying the nature of the failed event
In your failed events table, there is a column called contexts_com_snowplowanalytics_snowplow_failure_1 which contains information about why the event failed. All the other columns are as-is when the event was tracked and enriched.
The following query will show you all the failures in your failed events table, and make the fields easier to read:
- BigQuery
- Snowflake
SELECT
app_id,
event_name,
event_version,
contexts_com_snowplowanalytics_snowplow_failure_1,
contexts_com_snowplowanalytics_snowplow_failure_1[0].data AS data, -- use the `[0]` syntax to extract the first (and only) instance of this entity from the failure array
contexts_com_snowplowanalytics_snowplow_failure_1[0].errors AS errors,
contexts_com_snowplowanalytics_snowplow_failure_1[0].failure_type AS failure_type,
contexts_com_snowplowanalytics_snowplow_failure_1[0].schema AS schema,
contexts_com_snowplowanalytics_snowplow_failure_1[0].timestamp AS timestamp,
SPLIT(SPLIT(contexts_com_snowplowanalytics_snowplow_failure_1[0].schema,
'/')[0], ':')[1] AS schema_vendor,
SPLIT(contexts_com_snowplowanalytics_snowplow_failure_1[0].schema, '/')[1] AS schema_name,
SPLIT(contexts_com_snowplowanalytics_snowplow_failure_1[0].schema, '/')[3] AS schema_version
FROM `snowplow_failed.events` -- Use your failed events schema
WHERE 1=1
AND DATE(load_tstamp) > DATE_SUB(CURRENT_DATE(), INTERVAL 7 day) -- include a date range for when the failed events occurred
AND contexts_com_snowplowanalytics_snowplow_failure_1 IS NOT NULL
SELECT
app_id,
event_name,
event_version,
contexts_com_snowplowanalytics_snowplow_failure_1,
contexts_com_snowplowanalytics_snowplow_failure_1[0]:data AS data, -- use the `[0]` syntax to extract the first (and only) instance of this entity from the failure array
contexts_com_snowplowanalytics_snowplow_failure_1[0]:errors AS errors,
contexts_com_snowplowanalytics_snowplow_failure_1[0]:failure_type AS failure_type,
contexts_com_snowplowanalytics_snowplow_failure_1[0]:schema AS schema,
contexts_com_snowplowanalytics_snowplow_failure_1[0]:timestamp AS timestamp,
SPLIT_PART(SPLIT_PART(contexts_com_snowplowanalytics_snowplow_failure_1[0]:schema::STRING, '/', 1), ':', 2) AS schema_vendor,
SPLIT_PART(contexts_com_snowplowanalytics_snowplow_failure_1[0]:schema::STRING, '/', 2) AS schema_name,
SPLIT_PART(contexts_com_snowplowanalytics_snowplow_failure_1[0]:schema::STRING, '/', 4) AS schema_version
FROM SNOWPLOW_FAILED.EVENTS -- Use your failed events schema
WHERE load_tstamp::DATE > CURRENT_DATE - INTERVAL '7 DAY' -- include a date range for when the failed events occurred
AND contexts_com_snowplowanalytics_snowplow_failure_1 IS NOT NULL;
You can add additional filters to this query to isolate the specific failures you're interested in recovering:
- BigQuery
- Snowflake
WITH
failed_events AS (
SELECT
app_id,
event_name,
event_version,
contexts_com_snowplowanalytics_snowplow_failure_1,
contexts_com_snowplowanalytics_snowplow_failure_1[0].data AS data,
contexts_com_snowplowanalytics_snowplow_failure_1[0].errors AS errors,
contexts_com_snowplowanalytics_snowplow_failure_1[0].failure_type AS failure_type,
contexts_com_snowplowanalytics_snowplow_failure_1[0].schema AS schema,
contexts_com_snowplowanalytics_snowplow_failure_1[0].timestamp AS timestamp,
SPLIT(SPLIT(contexts_com_snowplowanalytics_snowplow_failure_1[0].schema,
'/')[0], ':')[1] AS schema_vendor,
SPLIT(contexts_com_snowplowanalytics_snowplow_failure_1[0].schema, '/')[1] AS schema_name,
SPLIT(contexts_com_snowplowanalytics_snowplow_failure_1[0].schema, '/')[3] AS schema_version
FROM `snowplow_failed.events` -- Use your failed events schema
WHERE 1=1
AND DATE(load_tstamp) > DATE_SUB(CURRENT_DATE(), INTERVAL 7 day)
AND contexts_com_snowplowanalytics_snowplow_failure_1 IS NOT NULL
ORDER BY timestamp DESC)
SELECT
event_name,
schema,
schema_name,
schema_version,
schema_vendor,
data,
errors,
data.user_name,
data.user_id
FROM failed_events
WHERE 1=1
AND schema_name = 'user_entity'
AND app_id = 'test-app'
ORDER BY timestamp DESC
WITH failed_events AS (
SELECT
app_id,
event_name,
event_version,
f.value AS failure_context,
f.value:data AS data,
f.value:errors AS errors,
f.value:failure_type AS failure_type,
f.value:schema AS schema,
f.value:timestamp AS timestamp,
SPLIT_PART(SPLIT_PART(f.value:schema::string, '/', 1), ':', 2) AS schema_vendor,
SPLIT_PART(f.value:schema::string, '/', 2) AS schema_name,
SPLIT_PART(f.value:schema::string, '/', 4) AS schema_version
FROM SNOWPLOW_FAILED.EVENTS, -- Use your failed events schema
LATERAL FLATTEN(input => contexts_com_snowplowanalytics_snowplow_failure_1) f -- using flatten allows for instances where multiple entities have failed on the same event
WHERE load_tstamp::DATE > CURRENT_DATE - INTERVAL '7 DAYS'
)
SELECT
event_name,
schema,
schema_name,
schema_version,
schema_vendor,
data,
errors,
data:user_name AS user_name,
data:user_id AS user_id,
FROM failed_events
WHERE schema_name = 'user_entity'
AND app_id = 'test-app'
ORDER BY timestamp DESC;
Here we are filtering for our test-app app ID, and the specific schema failures we're looking for (WHERE schema_name = 'user_entity').
The data field is a JSON object of the data that was included in the event, untouched from when it was tracked. We can access these using dot notation on the data object - e.g. data.user_name.
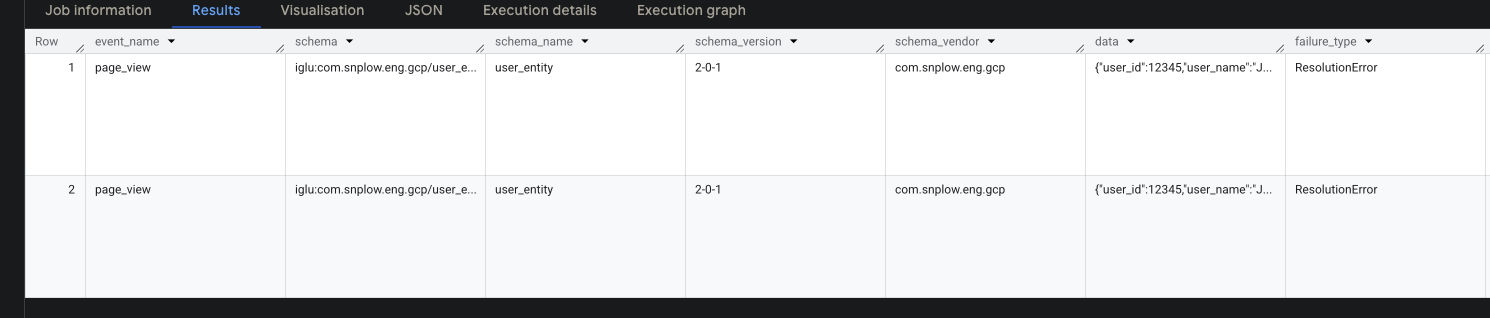
In this example, we can see that in the schema_version field, the version is 2-0-1 when the most up to date version of this schema is 2-0-0 and we've therefore had a ResolutionError in the failure_type column - meaning that Iglu wasn't able to find the schema that was included in the event. Therefore, we need to reconstruct the entity columns, with the correct schema version and the correct corresponding column name for that version. This is a relatively straightforward fix, as we don't have to mutate the data in place at all.
Reconstructing the failed event row
Even though this is a fairly straightforward fix (essentially in this case it is a passthrough) we must use some knowledge of how Snowplow constructs data in our good events table in order to correctly reconstruct the event before inserting.
Key principles for reconstructing events:
- The properties types defined in the JSON schema for an event or entity are deterministically converted into column types in the data warehouse.
- Custom events are analogous to JSON objects - key-value pairs of data on the event. The values in this object can be primitive types (strings, numbers, boolean values etc) or complex types (objects and arrays). The keys become the column names.
- Custom entities are stored as arrays of objects - this is because it is possible (and common) to attach multiple of the same entity to a single event - e.g. an array of
productentities being attached to aproduct_listevent. So even if there is only one of a given entity attached to an event, they are always stored as arrays in the data warehouse. Each entity object is semantically identical to that of a custom event i.e. a key-value object. - The
contexts_com_snowplowanalytics_snowplow_failure_1column is itself an array as it is an entity, and a single event can have multiple failures, each that should be addressed before reinserting. - The target column names also follow a deterministic naming convention:
- Custom event columns are of the format
unstruct_event_{vendor_name}_{schema_name}_{version_number | major_version_numer}. - Custom entity columns are of the format
contexts_{vendor_name}_{schema_name}_{version_number | major_version_numer}. - Column names also are "snake-ified", so camelCase names in your schemas will be converted to snake_case, and dots (
.) in your vendor name will also be snake-ified.
- Custom event columns are of the format
Creating a prep query
In this example, the user_entity is obviously an entity, so will be in an array. We're using BigQuery here, so we need an array containing a single struct value. In BigQuery, Snowplow stores the data object as a JSON type, so the individual values must be cast to their correct types.
- BigQuery
- Snowflake
WITH prep AS (
SELECT
contexts_com_snowplowanalytics_snowplow_failure_1
FROM `snowplow_failed.events`
WHERE 1=1
AND DATE(load_tstamp) > DATE_SUB(CURRENT_DATE(), INTERVAL 7 day)
AND app_id = 'test-app'
AND contexts_com_snowplowanalytics_snowplow_failure_1[0].schema = 'iglu:com.example/user_entity/jsonschema/2-0-1' -- filter for my offending schema
)
SELECT
ARRAY( -- since this is an entity, it must be an array
SELECT
STRUCT(
'2-0-0' AS _schema_version, -- set the schema version to the correct entity version for BigQuery Loader V2
INT64(contexts_com_snowplowanalytics_snowplow_failure_1[0].data.user_id) AS user_id, -- use the `[0]` syntax to extract the first (and only) instance of this entity from the failure array
STRING(contexts_com_snowplowanalytics_snowplow_failure_1[0].data.user_name) AS user_name -- use the `INT64(...)` and the `STRING(...)` functions to cast the raw JSON values to their appropriate types
)
)
AS contexts_com_example_user_entity_2_0_0 -- correctly name the column name to be inserted
FROM prep;
WITH prep AS (
SELECT contexts_com_snowplowanalytics_snowplow_failure_1
FROM SNOWPLOW_FAILED.EVENTS
WHERE load_tstamp::DATE > CURRENT_DATE - INTERVAL '7 DAY'
AND app_id = 'test-app'
AND contexts_com_snowplowanalytics_snowplow_failure_1[0]:schema = 'iglu:com.example/user_entity/jsonschema/2-0-1'
)
SELECT
ARRAY_CONSTRUCT( -- since this is an entity, it must be an array
OBJECT_CONSTRUCT(
'_schema_version', '2-0-0', -- set the schema version to the correct entity version for Snowflake Streaming Loader
'user_id', contexts_com_snowplowanalytics_snowplow_failure_1[0]:data:user_id::INT, -- use the `[0]` syntax to extract the first (and only) instance of this entity from the failure array
'user_name', contexts_com_snowplowanalytics_snowplow_failure_1[0]:data:user_name::STRING -- use the `...::INT` and the `...::STRING` functions to cast the raw JSON values to their appropriate types
)
) AS CONTEXTS_COM_EXAMPLE_USER_ENTITY_2
FROM prep
Reinserting the repaired rows
Now we have successfully identified our problematic rows and corrected them, we can now insert them back to the events table. While you can hand write an INSERT statement for the rows, the Snowplow events tables tend to have very large and complex table schemas, with hundreds or thousands of columns, with many complex nested columns. This process is time consuming and error prone, so we recommend using the INFORMATION_SCHEMA tables to programmatically construct the INSERT command before running it.
There are some complexities to bear in mind when doing this:
- There may well be columns that are not in the failed events table that are in the good events table. Your insert command must include
CAST(NULL AS ... )in place for all of those columns. - You must ensure that you have the correct structure for your repaired columns as otherwise they will not insert and the warehouse will reject the inserted rows.
- In newer versions of Snowplow data warehouse loaders (such as Snowflake Streaming Loader and the BigQuery Loader V2), entity columns also have a
_schema_versioncolumn. This must also be set for reprocessed entity columns in order for the insert to be successful. - If the recovered events are net-new to your good events table (say you've encountered failures on the first time using this schema) then that column won't exist in your good events table yet. We'd recommend sending a hand crafted good event for that schema to your prod pipeline first. This will allow the Snowplow loader to correctly create the column in your good events table so it is ready to be inserted into.
We would recommend using a staging table to insert the repaired rows before running this process on your main events table. This will allow you to review the repaired rows before inserting them into your main events table. To do so you can take a cut of your main events table, and run the INSERT command against that table, and verify you get the behavior you expect.
Below are scripts for BigQuery and Snowflake to create you the INSERT command:
- BigQuery
- Snowflake
-- Schema-aware INSERT generator for Snowplow failed events reprocessing
WITH target_table_columns AS ( -- this CTE finds all the columns in the good events table
SELECT
ordinal_position,
column_name,
data_type,
is_nullable
FROM `snowplow_good.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name = 'events'
AND table_schema = 'snowplow_good'
),
failed_table_columns AS ( -- this CTE finds all the columns in the failed events table
SELECT
column_name,
data_type,
is_nullable
FROM `snowplow_failed.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name = 'events'
AND table_schema = 'snowplow_failed'
),
schema_comparison AS ( -- this CTE joins the previous two, and labels them if they are missing
SELECT
t.ordinal_position,
t.column_name,
t.data_type AS target_type,
f.data_type AS failed_type,
t.is_nullable,
CASE
WHEN f.column_name IS NULL THEN 'MISSING_IN_FAILED'
ELSE 'MATCH'
END AS status
FROM target_table_columns t
LEFT JOIN failed_table_columns f ON t.column_name = f.column_name
),
column_mappings AS ( -- this CTE checks if columns are missing,
SELECT -- handles those missing columns by inserting NULLs
ordinal_position, -- and also inserts your repaired event columns
column_name,
target_type,
status,
CASE
-- Handle your specific replaced entity column
WHEN column_name = 'contexts_com_example_user_entity_2_0_0' THEN -- isolate the target column
-- paste in your reprocess logic as a string (including newline characters (`\n`) if you wish)
'''array(select struct(
\'2-0-0\' AS _schema_version,
int64(contexts_com_snowplowanalytics_snowplow_failure_1[0].data.user_id) AS user_id,
string(contexts_com_snowplowanalytics_snowplow_failure_1[0].data.user_name) AS user_name
)) AS contexts_com_example_user_entity_2_0_0'''
-- Exclude the failure entity from source
WHEN column_name = 'contexts_com_snowplowanalytics_snowplow_failure_1' THEN
'cast(null as array<struct<schema string, data json>>) AS contexts_com_snowplowanalytics_snowplow_failure_1'
-- Handle the load_tstamp column so that the inserted rows have the correct timestamp
WHEN column_name = 'load_tstamp' THEN 'current_timestamp() AS load_tstamp'
-- Handle missing columns with appropriate NULL casting
WHEN status = 'MISSING_IN_FAILED' THEN
CASE
-- Entity columns
WHEN STARTS_WITH(lower(column_name), 'contexts_') THEN
FORMAT('cast(null as %s) AS %s', target_type, column_name)
-- Standard columns
ELSE
FORMAT('cast(null as %s) AS %s', target_type, column_name)
END
-- Handle type mismatches with explicit casting
WHEN status = 'TYPE_MISMATCH' THEN
FORMAT('cast(%s as %s) AS %s', column_name, target_type, column_name)
-- Pass through matching columns
ELSE column_name
END AS select_expression
FROM schema_comparison
),
select_clause AS ( -- this CTE lists all the columns to go in the `INSERT` statement
SELECT STRING_AGG(select_expression, ',\n ' ORDER BY ordinal_position) AS columns_sql
FROM column_mappings
),
generated_insert AS (
SELECT FORMAT("""INSERT INTO `snowplow_good.events`
WITH prep AS (
SELECT
* -- include all columns from the failed events table
FROM `snowplow_failed.events`
WHERE DATE(load_tstamp) > DATE_SUB(CURRENT_DATE(), INTERVAL 7 day)
AND app_id = 'test-app'
AND contexts_com_snowplowanalytics_snowplow_failure_1[0].schema = 'iglu:com.example/user_entity/jsonschema/2-0-1'
)
SELECT
%s
FROM prep;""",
columns_sql
) AS insert_statement
FROM select_clause
)
-- Output the complete INSERT statement
SELECT
insert_statement AS generated_sql
FROM generated_insert
-- Schema-aware INSERT generator for Snowplow failed events reprocessing
WITH target_table_columns AS ( -- this CTE finds all the columns in the good events table
SELECT
ordinal_position,
column_name,
data_type,
is_nullable
FROM SNOWPLOW_GOOD_DATABASE.INFORMATION_SCHEMA.COLUMNS -- Use the database which has your SNOWPLOW_GOOD schema
WHERE lower(table_name) = 'events'
AND lower(table_schema) = 'snowplow_good'
),
failed_table_columns AS ( -- this CTE finds all the columns in the failed events table
SELECT
column_name,
data_type,
is_nullable
FROM SNOWPLOW_FAILED_DATABASE.INFORMATION_SCHEMA.COLUMNS --Use the database which has your SNOWPLOW_FAILED schema
WHERE lower(table_name) = 'events'
AND lower(table_schema) = 'snowplow_failed'
),
schema_comparison AS ( -- this CTE joins the previous two, and labels them if they are missing
SELECT
t.ordinal_position,
t.column_name,
t.data_type AS target_type,
f.data_type AS failed_type,
t.is_nullable,
CASE
WHEN f.column_name IS NULL THEN 'MISSING_IN_FAILED'
ELSE 'MATCH'
END AS status
FROM target_table_columns t
LEFT JOIN failed_table_columns f ON t.column_name = f.column_name
),
column_mappings AS ( -- this CTE checks if columns are missing,
SELECT -- handles those missing columns by inserting NULLs
ordinal_position, -- and also inserts your repaired event columns
column_name,
target_type,
status,
CASE
-- Handle your specific replaced entity column
WHEN column_name = 'CONTEXTS_COM_EXAMPLE_USER_ENTITY_2' THEN -- isolate the target column
-- paste in your reprocess logic as a string (newline characters (`\n`) also work)
'ARRAY_CONSTRUCT(
OBJECT_CONSTRUCT(
''_schema_version'', ''2-0-0'', -- set the schema version to the correct entity version for Snowflake Streaming Loader
''user_id'', contexts_com_snowplowanalytics_snowplow_failure_1[0]:data:user_id::INT,
''user_name'', contexts_com_snowplowanalytics_snowplow_failure_1[0]:data:user_name::STRING
)
) AS CONTEXTS_COM_EXAMPLE_USER_ENTITY_2'
-- Exclude the failure entity from source
WHEN column_name = 'contexts_com_snowplowanalytics_snowplow_failure_1' THEN
'CAST(NULL AS ARRAY<OBJECT<schema STRING, data VARIANT>>) AS contexts_com_snowplowanalytics_snowplow_failure_1'
-- Handle the load_tstamp column so that the inserted rows have the correct timestamp
WHEN column_name = 'load_tstamp' THEN 'CURRENT_TIMESTAMP() AS load_tstamp'
-- Handle missing columns with appropriate NULL casting
WHEN status = 'MISSING_IN_FAILED' THEN
CASE
-- Entity columns
WHEN STARTSWITH(lower(column_name), 'contexts_') THEN
CONCAT('CAST(NULL AS ', target_type, ') AS ', column_name)
-- Standard columns
ELSE
CONCAT('CAST(NULL AS ', target_type, ') AS ', column_name)
END
-- Handle type mismatches with explicit casting
WHEN status = 'TYPE_MISMATCH' THEN
CONCAT('CAST(', column_name, ' AS ', target_type, ') AS ', column_name)
-- Pass through matching columns
ELSE column_name
END AS select_expression
FROM schema_comparison
),
select_clause AS ( -- this CTE lists all the columns to go in the `INSERT` statement
SELECT LISTAGG(select_expression, ',\n ') WITHIN GROUP (ORDER BY ordinal_position) AS columns_sql
FROM column_mappings
),
generated_insert AS (
SELECT CONCAT(
'INSERT INTO SNOWPLOW_GOOD.EVENTS
WITH prep AS (
SELECT * -- include all columns from the failed events table
FROM SNOWPLOW_FAILED.EVENTS
WHERE load_tstamp::DATE > CURRENT_DATE - INTERVAL ''7 DAY''
AND app_id = ''test-app''
AND contexts_com_snowplowanalytics_snowplow_failure_1[0]:schema = ''iglu:com.example/user_entity/jsonschema/2-0-1''
)
SELECT
',
columns_sql,
'
FROM prep;'
) AS insert_statement
FROM select_clause
)
-- Output the complete INSERT statement
SELECT
insert_statement AS generated_sql
FROM generated_insert;
This will print out the correctly formatted INSERT statement. You can now copy this and run it against your data warehouse, and it will reinsert the newly repaired failed events back into your good events table.